|
|
|
|
Analiza Factoriala - scurta trecere in revista
1. Principii: variabile latente si manifeste
Fenomenele sociale sunt de regula agregate complexe, greu de masurat printr-un singur item (printr-o singura intrebare). De exemplu, religiozitatea este o trasatura interioara care se manifesta prin diverse trasaturi: frecventa mersului la Biserica, Credinta in Dumnezeu (sau in Alah .), increderea in explicatia pe care Biserica o da lumii si vietii, frecventa rugaciunilor etc. Similar, stilul de viata se manifesta prin optiunile legate de timpul liber (frecventa mersului la bar, la gym, preferinta pentru ascensiuni montane, canal TV preferat etc.), de relatiile sociale (criteriile de selectie a prietenilor, frecventa intalnirii cu ei etc.), de viata de familie, de alte preferinte de consum (marca de vin favorita, sportul preferat, mobila preferata etc.) etc.
Atat religiozitatea, cat si stilul de viata sunt fenomene complexe, realitati latente care se manifesta prin diverse laturi ale lor. Insa nici una din aceste manifestari (mersul la biserica sau preferinta de consum, de exemplu) nu reuseste sa surprinda intreaga complexitate a fenomenului masurat. Doar ansamblul tuturor manifestarilor poate face acest lucru.
Jargon:
Latente
Manifeste
Factori
Indicatori
Explicatii
Explicate
Dimensiuni
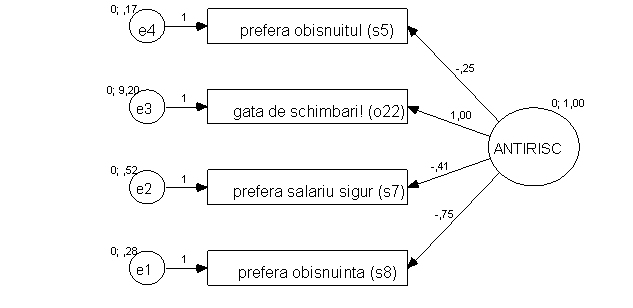
Alt exemplu: vezi mai sus =>
Latenta este atitudinea de evitare a riscului. Restul sunt manifeste
(intrebari la care subiectul a raspuns in chestionar).
Analiza factoriala reprezinta o metoda de reducere a complexitatii datelor. Dintr-un set de 8-12 variabile se pot extrage usor factorii care le explica. Cu alte cuvinte pot fi identificate dimensiunile latente ale spatiului de alegeri ale subiectilor.
Daca variabile explicate sunt X1 . Xk, iar factorii explicativi sunt F1 . Fs, atunci:
![]()
![]()
etc.
Coeficientii bij se numesc coeficienti de saturatie si reprezinta masuri ale influentei Factorului Fj asupra lui Xi. (intuitiv sunt niste "corelatii" intre factori si variabile).
Analiza factoriala cu SPSS - mod de producere
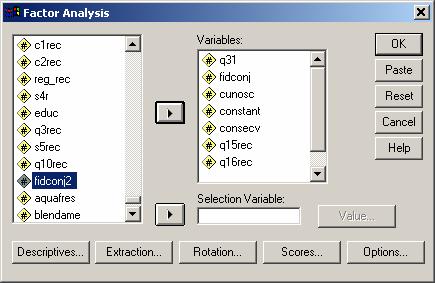
Variabilele analizate trebuie sa fie continue sau dummy. Numarul de cazuri trebuie sa fie egal cu cel putin 5 inmultit cu numarul de variabile.
Optiunile selectate:
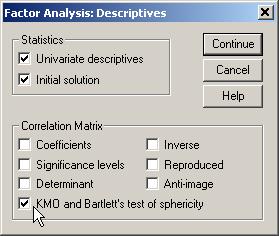 KMO este un indice al adecvarii analizei factoriale
la date. Ia valori de la 0 la 1.
KMO este un indice al adecvarii analizei factoriale
la date. Ia valori de la 0 la 1.
Un KMO sub 0,600 indica faptul ca analiza factoriala nu este potrivita pentru datele utilizate.
KMO intre 0,600 si 0,700 este interpretat de regula drept bun, insa numai daca teoria (explicatia) la dispozitie este una puternica, de incredere, eventual validata extern.
Peste 0,700 totul e minunat. Cu cat mai mare cu atat mai bine! ATENTIE INSA: KMO creste automat pe masura ce creste numarul de variabile. La peste 12-14 variabile, KMO sub 0,800 reprezinta deja un semnal de alarma!!
Exista doua metode de a stabili numarul de dimensiuni (factori). Prima este de a considera drept dimensiuni factorii cu valori proprii de peste 1. A doua este utilizarea testului grohotisului (revin asupra lor la interpretarea output-ului):
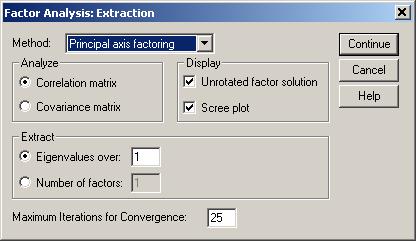
Regula extragerii factorilor cu valori proprii peste 1 este optiunea implicita din SPSS. Poate fi schimbata in optiunile de la "Extraction", schimband valoarea lui 1 cu alta cifra sau specificand numarul de factori care trebuie extrasi.
Metoda de extractie: Principal axis factoring este preferabila celorlalte optiuni.
Metodele de rotire. Dupa identificarea numarului de factori caut sa ii fac cat mai interpretabili fie factorii, fie variabilele, fie ambele (calea de compromis). Pentru aceasta folosesc metode de rotire:
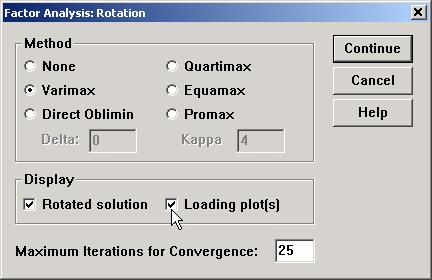
Varimax: minimizeaza numarul variabilelor care coreleaza puternic cu fiecare factor in parte. Cu alte cuvinte, fiecare factor (dimensiune) va explica un set mai restrans de variabile, fiind mai usor de interpretat
Quartimax: Opusul varimax, minimizeaza numarul de factori care explica o variabila. Factorii sunt mai greu de interpretat (de gasit un nume pentru ei), insa fiecare variabila este mai bine explicata.
Equamax: cauta o cale de compromis intre cele doua.
Toate cele trei metode produc factori ortogonali (intre care corelatia este nula).
Direct Oblimin si Promax produc factori neortogonali (care pot corela intre ei).
Preferinta pentru una din metodele de rotire apare in functie de analiza realizata. (de retinut insa ca, in principiu, diferentele nu sunt mari pentru seturi de 10-15 variabile explicate). In studiul de piata este preferata in genere Varimax. Cercetatorii din stiintele sociale folosesc insa mai ales Equamax.
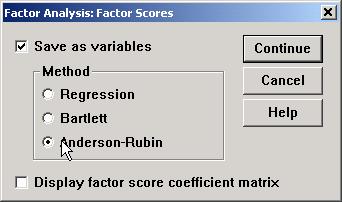 Cunoscand coeficientii de
saturatie (bij) si valorile fiecarui X se poate
calcula valoarea pe care fiecare factor o ia pentru fiecare individ in parte,
astfel incat sa putem compara indivizii intre ei (sa folosim aceste
serii de valori in analize de regresie, ANOVA, cluster, alte analize factoriale
etc.). Metodele cele mai utilizate sunt "Regression" si "Anderson-Rubin".
O recomand pe ultima.
Cunoscand coeficientii de
saturatie (bij) si valorile fiecarui X se poate
calcula valoarea pe care fiecare factor o ia pentru fiecare individ in parte,
astfel incat sa putem compara indivizii intre ei (sa folosim aceste
serii de valori in analize de regresie, ANOVA, cluster, alte analize factoriale
etc.). Metodele cele mai utilizate sunt "Regression" si "Anderson-Rubin".
O recomand pe ultima.
In submeniul "Options"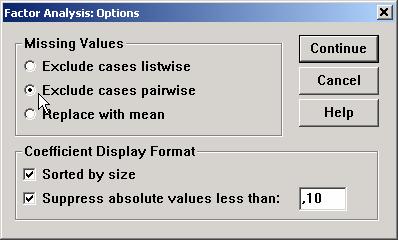 , cele cateva optiuni pe care le
recomand sunt cele de mai jos. "Pairwise" maximizeaza numarul de date
luate in analiza, fapt extrem de util cand folosim date cu multe missing
cases. Evitati intotdeauna "Replace by mean".
, cele cateva optiuni pe care le
recomand sunt cele de mai jos. "Pairwise" maximizeaza numarul de date
luate in analiza, fapt extrem de util cand folosim date cu multe missing
cases. Evitati intotdeauna "Replace by mean".
Cele doua optiuni din partea de jos se refera la modul de afisare a saturatiilor in output. Sortarea si neafisarea valorilor corelatiilor foarte mici usureaza citirea matricei de saturatii si interpretarea factorilor.
Interpretarea output-ului de SPSS
1. Ma uit mai intai daca modelul este adecvat datelor folosite:
 Ceea ce intereseaza este mai ales KMO. Reamintesc ca intre 0,6
si 0,7 este discutabil, peste 0,7 este bun cand avem mai putin de 10-12
variabile, iar daca avem multe variabile, atunci este necesar sa un
KMO de peste 0,800.
Ceea ce intereseaza este mai ales KMO. Reamintesc ca intre 0,6
si 0,7 este discutabil, peste 0,7 este bun cand avem mai putin de 10-12
variabile, iar daca avem multe variabile, atunci este necesar sa un
KMO de peste 0,800.
Ce fac daca am un KMO prost ?
Nici o problema: ma uit mai intai la comunalitati (de altfel, ma uit acolo si daca am un KMO bun!), rezolv acolo problemele si apoi o sa am si un KMO bun. Daca nu s-a rezolvat inca problema, este foarte posibil ca sa incerc sa aplic analiza factoriala unui set de variabile care nu fac parte dintre indicatorii acelorasi realitati latente!!! Adica nu am de ce sa fac aici analiza factoriala!
Comunalitatile dau o masura a variatiei fiecarei variabile explicata de factorii extrasi (un soi de R2 al unei regresii in care dependenta este variabila in cauza, iar independentele toate celelalte variabile). Cu alte cuvinte, o comunalitate mica, aproape de 0, indica faptul ca variabila respectiva nu are ce cauta in setul de date analizate, nu face parte din aceeasi dimensiune/dimensiuni cu restul variabilelor. Pe mine unul ma ingrijoreaza comunalitati de la 0,2 in jos, iar cand KMO e mic, caut sa vad daca nu sunt probleme cu variabilele care au comunalitati intre 0,2 si 0,3.

SPSS foloseste un procedeu de extractie iterativ, in prima iteratie fiind extras un numar de factori egal cu numarul de variabile. De aceea sunt raportate comunalitati initiale si finale ("Extraction"). Interesante sunt cele finale.
Un alt procedeu de a afla daca nu cumva sunt variabile care nu au ce cauta in analiza factoriala alaturi de celelalte este sa investighezi matricea de corelatii si sa observi daca nu cumva o variabila are corelatii mici cu toate celelalte variabile din setul analizat. Practic, acea variabila este cea care va avea o comunalitate mica. De aceea recomand simpla investigare a tabelei de comunalitati.
Problema numarului de factori extrasi este esentiala in analiza factoriala. Factorii trebuie sa explice cat mai mult din variatia spatiului optiunilor analizate, trebuie sa fie cat mai usor de interpretat/etichetat (cu alte cuvinte trebuie sa aiba consistenta teoretica) si trebuie sa fie . cat mai putini!
Exista doua reguli generale care functioneaza pentru extractia factorilor:
1. Testul grohotisului
2. regula extragerii factorilor cu valori proprii peste 1 (cu alte cuvinte, a extragerii factorilor care explica destul de mult din variatia totala)
Testul grohotisului: este o metoda grafica de extractie. Sunt urmarite pe grafic scaderile bruste de la o valoare proprie la o alta. Sunt extrasi doar factorii de deasupra intreruperii (locului in care panta devine foarte abrupta). De pilda, in cazul de mai jos, testul grohotisului sugereaza extragerea unui singur factor.
![]()
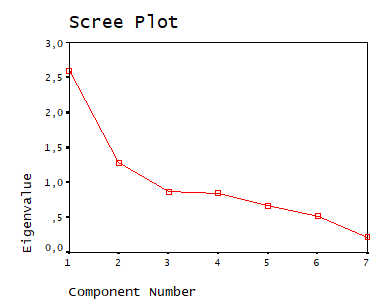
In exemplele urmatoare, testul grohotisului sugereaza cate doi factori:
![]()
![]()
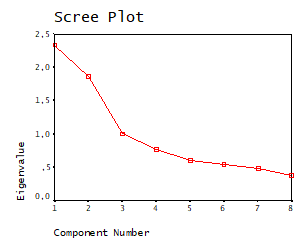
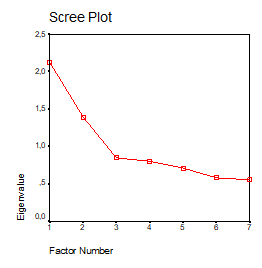
Regula extragerii tuturor factorilor cu valoarea mai mare decat 1

Este optiunea implicita din SPSS. Poate fi schimbata in optiunile de la "Extraction", schimband valoarea lui 1 cu alta cifra sau specificand numarul de factori care trebuie extrasi.
In tabelul de mai sus, variatia explicata de un factor este calculata ca raport intre valoarea proprie a factorului si suma valorilor proprii a tuturor factorilor posibili. Suma valorilor proprii nu poate depasi numarul de factori. De aici regula intuitiva a extragerii factorilor cu valori peste 1: "ei explica mai mult decat variatia unei singure variabile".
Optiunea mea este sa utilizez in mod complementar cele doua reguli. In plus ele trebuie corelate si cu matricea saturatiilor, cea care ne permite sa interpretam factorii. Daca, de exemplu, testul grohotisului sugereaza un singur factor, iar valorile proprii 2 factori, acord credit tabelului cu saturatii. Daca exista sustinerea teoretica pentru doi factori (cei doi factori extrasi si apoi rotiti sunt interpretabili si consistenti), atunci optez pentru doi factori.
In caz contrar aleg doar unul. In cazul in care sunt extrasi mai multi factori si sunt intr-o analiza exploratorie, atunci rulez analiza factoriala cu 3, 4, 5 factori, pana obtin factori interpretabili, consistenti cu una din regulile de extragere si care nu se abat mult de la cealalta si care explica macar 40-45% din variatia variabilelor analizate. Daca extrag mai multi factori (de exemplu 4-5) ei sa explice peste 40-45%. In cazul a 1-2 factori ma pot multumi si cu mai putin 35-40%. Acestea sunt insa minime. Satisfactia maxima o obtin la explicatii cumulate de cel putin 50%, iar peste 60% e de-a dreptul minunat. Peste 80% imi pun intrebari legate de acuratetea datelor, insa teoretic pot obtine si astfel de valori.

Matricea saturatiilor
In acest caz sugereaza ca extragerea a doi factori produce factori usor de interpretat si consistenti teoretic. Ar fi un factor de fidelitate declarata (primul factor) si unul fidelitate in recunoasterea marcii.
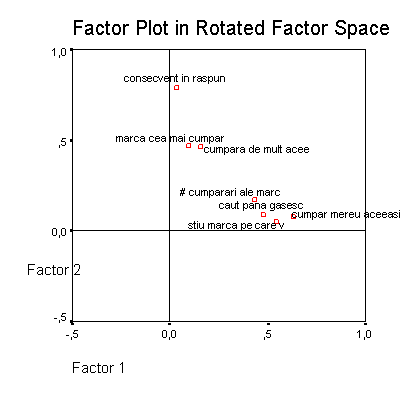
O metoda simpla de a prezenta rezultatele si de a interpreta mai usor factorii este prezentarea lor grafica (loading plots). Cei doi factori sunt descrisi destul de clar grafic, daca etichetele nu se suprapun una peste alta J. "Loading plot(s)" nu sunt afisate daca nu am solicitat acest lucru in meniul de la "Rotation".
Revenind la saturatii sa notam ca e bine ca fiecare factor sa aiba macar 3 indicatori (3 variabile cu care sa coreleze mai puternic), dar nici doi nu sunt de lepadat. Pe de alta parte trebuie ca factorii sa aiba fiecare cam acelasi numar de indicatori.
In matricea saturatiilor de mai sus, unele valori nu sunt afisate fiind mai mici de 0,10 (optiunea din meniul "Options").