|
|
|
|
SISTEME DE OPERARE PENTRU CALCULATOARE PARALELE
1. NOTIUNI INTRODUCTIVE
Platformele hardware pentru programare paralela sunt:
-tablouri de procesoare;
-multiprocesoare;
-multicalculatoare;
-retele de calculatoare (statie de lucru in LAN).
In functie de platformele hardware exista urmatoarele tipuri de sisteme de operare:
-sisteme de operare in retea, pentru platforme hardware de tip multicalculatoare;
-sisteme de operare cu multiprocesoare, pentru platforme hardware de tip multiprocesoare;
-sisteme de operare distribuite, pentru platforme hardware de tip multicalculatoare.
Denumirea de sisteme de operare distribuite se gaseste in literatura de specialitate, in unele cazuri, pentru toate calculatoarele paralele. In ultimul timp, insa, s-a impus termenul de distribuit numai pentru multicalculatoare, astfel incat termenul sisteme de operare distribuite inseamna sisteme de operare numai pentru multicalculatoare.
O alta problema esentiala intr-un calculator paralel este distributia sarcinilor intre sisteme de operare, programe, compilatoare; nici in ziua de astazi nu lucrurile nu sunt prea clare in ceea ce priveste rolul fiecaruia.
Limbajele de programare in calculatoarele paralele pot fi la randul lor clasificate in:
-limbaje de programare paralela, pentru programarea prin variabile partajate, pe multiprocesoare;
-limbaje de programare distribuita, pentru programarea prin transfer de mesaje, folosita in multicalculatoare.
In prezent exista un mare numar de limbaje de programare paralela si distribuita. Aceste limbaje sunt de doua categorii:
-limbaje paralele si distribuite dezvoltate din limbaje secventiale uzuale ca: Fortran, Pascal, C; astfel de limbaje sunt limbajele Power Fortran, Power C, C*.
-limbaje paralele si distribuite noi, scrise special pentru multiprocesoare si multicalculatoare; astfel de limbaje sunt limbajele Occam, Orca, Ada, Parlog, SR, Emerald.
O alta clasificare a limbajelor de programare paralele, legata de tipul compilatoarelor, este:
-limbaje de programare paralela explicite;
-limbaje de programare paralela implicite.
In limbajele de programare paralela explicite, programatorul este acela caruia ii revine sarcina de a descrie algoritmul paralel in mod explicit, specificand activitatile paralele precum si modul de comunicare si sincronizare a proceselor sau threadurilor.
In limbajele de programare paralela implicite, compilatorul este acela care detecteaza paralelismul algoritmului prezentat ca un program secvential si genereaza codul corespunzator pentru executia activitatilor paralele pe procesoarele componente ale calculatorului. Astfel de compilatoare se mai numesc compilatoare cu paralelizare caci au sarcina de a paraleliza programul. Dezvoltarea acestor compilatoare este limitata de dificultatea de a detecta si analiza dependentele in programele complexe. Paralelizarea automata a programelor este mai usor de executat pentru paralelismul la nivel de instructiune, in care se distribuie instructiunile unei bucle, si este mai greu de facut pentru programele cu o structura neregulata, care prezinta apeluri multiple de functii, proceduri, ramificatii sau bucle imperfect imbricate. Un exemplu de astfel de compilatoare este cel al multiprocesoarelor Silicon Graphics in care se ruleaza Power C si care includ un analizor de sursa ce realizeaza paralelizarea automata a programelor.
Din punct de vedere al sistemelor de operare intereseaza aspectele de cuplare ale hardului si softului.
Din punct de vedere al hardului, multiprocesoarele sunt puternic cuplate iar multicalculatoarele sunt slab cuplate.
Din punct de vedere al softului, un sistem slab cuplat permite calculatoarelor si utilizatorilor unui sistem de operare o oarecare independenta si, in acelasi timp, o interactionare de grad limitat. Intr-un sistem software slab cuplat, intr-un grup de calculatoare fiecare are memorie proprie, hardware propriu si un sistem de operare propriu. Deci calculatoarele sunt aproape independente in functionarea lor. Un defect in reteaua de interconectare nu va afecta mult functionarea calculatoarelor, desi unele functionalitati vor fi pierdute.
Un sistem soft puternic cuplat are in componenta programe de aplicatii care interactioneaza mult intre ele dar si cu sistemul de operare.
Corespunzator celor doua categorii de hardware (slab si puternic cuplat) si celor doua categorii de software (slab si puternic cuplat), exista patru categorii de sisteme de operare, dintre care trei au corespondent in implementarile reale.
2. SISTEME DE OPERARE IN RETEA
Sistemele de operare din aceasta categorie au:
-hardware slab cuplat;
-software slab cuplat.
Fiecare utilizator are propriul sau workstation, cu un sistem de operare propriu care executa comenzi locale. Interactiunile care apar nu sunt puternice. Cel mai des apar urmatoarele interactiuni:
-conectarea ca user intr-o alta statie, ceea ce are ca efect transformarea statiei proprii intr-un terminal la distanta al statiei la care s-a facut conectarea;
-utilizarea unui sistem de fisiere global, accesat de toate statiile din retea, plasat intr-una din statii, denumita server de fisiere.
Sistemele de operare din aceasta categorie au sarcina de a administra statiile individuale si serverele de fisiere si de a asigura comunicatiile dintre acestea. Nu este necesar ca pe toate statiile sa ruleze acelasi sistem de operare. Cand pe statii ruleaza sisteme de operatii diferite, statiile trebuie sa accepte toate acelasi format al mesajelor de comunicatie.
In sistemele de operare de tip retea nu exista o coordonare in executia proceselor din retea, singura coordonare fiind data de faptul ca accesul la fisierele nelocale trebuie sa respecte protocoalele de comunicatie ale sistemului.
3. SISTEME DE OPERARE CU MULTIPROCESOARE
Aceste sisteme de operare au:
-hardware puternic cuplat;
-software puternic cuplat.
In astfel e sistem hardul este mai dificil de realizat decat sistemul de operare. Un sistem de operare pentru sisteme cu multiprocesoare nu difera mult de fata de un sistem de operare uniprocesor.
In ceea ce priveste gestiunea proceselor, faptul ca exista mai multe procesoare hard nu schimba structura sistemului de operare. Va exista o coada de asteptare unica a proceselor pentru a fi rulate, organizata exact dupa aceleasi principii ca la sisteme uniprocesor. La fel, gestiunea sistemului de intrare/iesire si gestiunea fisierelor raman practic neschimbate.
Cateva modificari sunt aduse gestiunii memoriei. Accesul la memoria partajata a sistemului trebuie facuta intr-o sectiune critica, pentru prevenirea situatiei in care doua procesoare ar putea sa aleaga acelasi proces pe care sa-l planifice in executie simultana. Totusi, de cele mai multe ori, accesul la memoria partajata trebuie sa fie facuta de programator, adica de cel care proiecteaza aplicatia. Sistemul de operare pune la dispozitie mijloacele standard (semafoare, mutexuri, monitoare) pentru implementarea realizarii sectiunii critice, mijloace care sunt aceleasi ca la sistemele uniprocesor. De aceea, sistemele de operare pentru multiprocesoare nu trebuie fundamental tratate altfel decat sistemele de operare pentru uniprocesoare.
3.1. Programarea paralela
In programarea paralela, mai multe procese sau threaduri sunt executate concurent, pe procesoare diferite, si comunica intre ele prin intermediul variabilelor partajate memorate in memoria comuna. Avantajele programarii paralele sunt:
- o viteza de comunicare intre procese relativ ridicata;
- o distributie dinamica a datelor;
- o simplitate de partitionare.
3.1.1. Memoria partajata intre procese
Deoarece in programarea paralela memoria partajata joaca un rol important, sa prezentam cateva caracteristici ale acesteia.
Am vazut, in capitolele anterioare, ca fiecare proces are un spatiu virtual de procese alcatuit din:
-cod;
-date;
-stiva.
Un proces nu poate adresa decat in acest spatiu iar alte procese nu au acces la spatiul de memorie al procesului respectiv.
In memoria partajata, modalitatea prin care doua sau mai multe procese pot accesa o zona de memorie comuna este crearea unui segment de memorie partajata. Un proces creeaza un segment de memorie partajata definindu-i dimensiunea si drepturile de acces. Apoi amplaseaza acest segment in propriul spatiu de adrese. Dupa creare, alte procese pot sa-l ataseze si sa-l amplaseze in spatiul lor de adrese. Esential este ca segmentul de memorie sa fie creat in memoria principala comuna si nu intr-una din memoriile locale.
3.1.2. Exemple de programare paralela
Modelul PRAM
Modelul PRAM (Parallel Random Acces Machines) a fost dezvoltat de Fortane si Willie pentru modelarea unui calculator paralel cu cost suplimentar de sincronizare si acces la memorie nul. El contine procesoare care acceseaza o memorie partajata. Operatiile procesoarelor la memoria partajata sunt:
- citirea exclusiva (Exclusive Read ,ER) ; se permite ca un singur procesor sa citeasca dintr-o locatie de memorie, la un moment dat;
- scriere exclusiva ( Exclusive Write, EW); un singur procesor va scrie intr-o locatie de memorie, la un moment dat;
- citire concurenta (Concurrent Read, CR); mai multe procesoare pot sa citeasca o locatie de memorie la un moment dat;
- scriere concurenta (Concurent Write, CW); mai multe procesoare pot sa scrie intr-o locatie de memorie la un moment dat.
Combinand aceste operatii, rezulta urmatoarele modele:
EREW, cu citire si scriere concurenta; este modelul cel mai restrictiv in care numai un singur procesor poate sa scrie sau sa citeasca o locatie de memorie la un moment dat;
CREW, cu citire concurenta si scriere exclusiva; sunt permise accese concurente doar in citire, scrierea ramanand exclusiva;
ERCW, cu citire exclusiva si scriere concurenta; sunt permise accese concurente in scriere, citirea ramanand exclusiva;
CRCW, cu citire si scriere exclusiva; sunt permise accese concurente de scriere si citire la aceiasi locatie de memorie.
Scrierea concurenta (CW) se rezolva in urmatoarele moduri:
COMMON PRAM, operatiile de scriere memoreaza aceiasi valoare la locatia accesata simultan.
MINIMUM PRAM, se memoreaza valoarea scrisa de procesorul cu indicele cel mai mic.
ARBITRARY PRAM, se memoreaza numai una din valori, aleasa arbitrar.
PRIORITY PRAM, se memoreaza o valoare obtinuta prin aplicarea unei functii asociative ( cel mai adesea insumarea) tuturor valorilor cu care se acceseaza locatia de memorie.
Algoritmi PRAM
Pentru algoritmii paraleli se foloseste un limbaj de nivel inalt (de exemplu C) la care se adaoga doua instructiuni paralele
1) forall<lista de procesare>do
<lista instructiuni>
endfor
Se executa, in paralel, de catre mai multe procesoare (specificate in lista de procesoare) unele operatii (specificate in lista de instructiuni).
2) parbegin
<lista de instructiuni>
parend
Se executa, in paralel, mai multe instructiuni (specificate in lista de instructiuni).
Program paralel de difuziune
Operatia de difuziune (broadcast) consta din transmiterea unei date catre toate procesele din sistem. Daca exista o data intr-o locatie din memoria partajata, ea va trebui transmisa catre celelalte n procesoare. Modelul ales este EREW.
Daca procesoarele ar citi fiecare valoare din locatie, pentru n procesoare, ar rezulta o functie de tip O(n),deci un timp liniar care este mare si nu exploateaza posibilitatea de executie concurenta a mai multor procesoare.
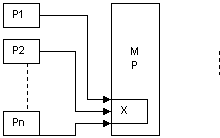
P1 acceseaza x
P2 acceseaza x
Pn acceseaza Xx
rezulta
o functie O(n)
x= locatie de memorie
Fig. 1. Program paralel de difuziune (model EREW).
Solutia de difuziune presupune urmatorii pasi.
- Se alege un vector a[n[, n fiind numarul de procesoare in memorie partajata.
- Data de difuzat este a[0] si in memoria locala a procesorului P0 .
-In primul pas , la iteratia j=0, procesorul P1 citeste data din a[0], o inscrie in memoria locala si in vectorul partajat in pozitia a[1].
- In al doilea pas, la iteratia j=1, procesoarele P2 si P3 citesc data din a[0] si a[1], o inscriu in memoria locala si in locatiile a[2] si a[3].
- In general, in iteratia j, procesoarele i, cu conditia 2j≤i<2j+1 , citesc data de difuzat de la locatiile a[i-2j], o memorizeaza in memoria locala si o inscriu in vector in locatiile a[i].
Iata un exemplu pentru n=8 procesoare. Data de difuzat initiala este 100.
Initial
a[0]
a[1]
a[2]
a[3]
a[4]
a[5]
a[6]
a[7]
100
100
P0
P1
P2
P3
P4
P5
P6
P7
Primul pas
(iteratia j=0)
a[0]
a[1]
a[2]
a[3]
a[4]
a[5]
a[6]
a[7]
![]() 100
100
![]() 100
100
100
100
P0
P1
P2
P3
P4
P5
P6
P7
Al doilea pas
(iteratia j=1)
a[0]
a[1]
a[2]
a[3]
a[4]
a[5]
a[6]
a[7]
100
![]() 100
100
![]() 100
100
![]() 100
100
100
100
100
100
P0
P1
P2
P3
P4
P5
P6
P7
Al treilea pas
(iteratia j=2)
a[0]
a[1]
a[2]
a[3]
a[4]
a[5]
a[6]
a[7]
100
100
100
100
![]() 100
100
![]() 100
100
![]() 100
100
![]() 100
100
![]()
![]()
![]()
![]()
100
100
100
100
100
100
100
100
P0
P1
P2
P3
P4
P5
P6
P7
Deoarece la fiecare iteratie se dubleaza numarul de procesoare care au receptionat data de difuzat, sunt necesare log2n iteratii. Intr-o iteratie j, sunt active 2j procesoare, cele cu indice i avand 2j≤i<2j+1 .
Timpul de executie este estimat de O(log n), deci un timp sublinear.
Iata o implementare a difuziunii intr-un limbaj formal PRAM, in EREW:
DIFUZIUNEA:
int n, a[n];
forall(0≤i<n)do
for(j=0; j<log n; j++)
if(2j<=i<2j+1)
endfor
Program paralel de reducere
Fiind date n valori ca elemente ale unui vector si operatia de adunare ,+, reducerea este operatia:
a[1]+a[2]+a[3]+..+a[n]
Implementarea secventiala a reducerii este:
for(i=1;i<n;i++)
a[0]+=a[i]
Se observa ca rezultatul reducerii se gaseste in prima componenta a vectorului a[0]. La fel ca si la difuziune, implementarea secventiala duce la un timp O(n).
Algoritmul paralel de reducere este unul de tip EREW, utilizand m/2 procesoare. Se considera initial datele intr-un vector a[n], pentru simplificare luandu-se n ca multiplu de doi. Pasii sunt urmatorii:
- in primul pas, iteratia j=0, toate procesoarele Pi(0≤i<n/2) sunt active si fiecare aduna doua valori a[2i] si a[2i+1] , rezultatul fiind a[2i] ;
- in al doilea pas, iteratia j=1, sunt active procesoarele Pi , cu i=1 si i=2, care aduna a[2i] cu a[2i+2], rezultatul fiind a[2i] ;
- in general, in iteratia j, sunt active procesoarele cu indice i, multiplu de 2; fiecare actualizeaza locatia a[2i], deci executa a[2i]=a[2i]+a[2i+2].
Se observa ca numarul de iteratii j este log2n , deci avem un timp de executie de tip O(log n), un algoritm sublinear.
Dam mai jos un exemplu de implementare pentru n=8 .
P0 P1P2 P3
Iteratie
a[0]
a[1]
a[2]
a[3]
a[4]
a[5]
a[6]
a[7]
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
j=0
a[0]
a[2]
a[4]
a[6]
![]()
![]()
![]()
j=1
![]()
![]() a[0]
a[0]
a[4]
j=2
a[0]
Fig. 2. Program paralel reducere (model EREW)
REDUCERE
int n, a[n];
forall(0≤i<n/2)do
for(j=0;j<log n;j++)
if(i modulo 2j+1==0)
a[2i]=a[2i+2j];
endfor
4. SISTEME DE OPERARE DISTRIBUITE
Aceste sisteme fac parte din categoria
hardware slab cuplat (multicalculatoare)
software puternic cuplat.
Din punct de vedere hardware, un astfel de sistem, tip multicalculator, este usor de realizat. Un multicalculator este format din mai multe procesoare, fiecare procesor avand propria unitate de control si o memorie locala. Procesoarele sunt legate intre ele printr-o retea de comutatie foarte rapida. O astfel de arhitectura hardware prezinta o serie de avantaje:
- adaugarea de noi procesoare nu conduce la degradarea performantelor;
- un astfel de sistem multicalculator permite folosirea mai eficienta a procesoarelor; in general, un utilizator solicita inegal in timp un calculator, existand perioade in care unitatea centrala nu este incarcata si perioade in care este foarte solicitata (la programe cu calcule foarte multe, de exemplu la un sistem liniar cu multe ecuatii si necunoscute); intr-un sistem distribuit incarcarea procesoarelor se face mult mai bine, marindu-se mult viteza de calcul;
- sistemul poate fi modificat dinamic, in sensul ca se pot inlocui procesoare vechi cu unele noi si se pot adauga unele noi, cu investitii mici, fara sa fie nevoie de reinstalare de soft sau reconfigurare de resurse.
Din punct de vedere al sistemului de operare, insa, lucrurile se complica. Este foarte dificil de implementat un sistem de operare distribuit. Sunt de rezolvat multe probleme legate de comunicatie, sincronizare , consistenta informatiei etc.
Scopul acestor sisteme de operare distribuite este de a crea impresia utilizatorului ca tot multicalculatorul este un singur sistem multitasking si nu o colectie de calculatoare distincte. De fapt, un multicalculator ar trebui sa aiba o comportare de uniprocesor virtual. Ideea este ca un utilizator sa nu fie preocupat de existenta mai multor calculatoare in sistem.
Un sistem de operare distribuit trebuie sa prezinte anumite caracteristici:
- sa existe un singur mecanism de comunicare intre procese, astfel incat fiecare proces sa poata comunica cu altul, indiferent daca acesta este local sau nelocal; multimea apelurilor sistem trebuie sa fie aceeasi si tratarea lor identica;
- sistemul de fisiere trebuie sa fie acelasi pentru toate statiile componente, fara restrictii de lungime a numelor fisierelor si cu aceleasi mecanisme de protectie si securitate;
- pe fiecare procesor trebuie sa ruleze acelasi kernel.
Problema esentiala care se pune acum in sistemele distribuite este impartirea sarcinilor intre sistemul de operare, programatorul de operatii si compilator. La ora actuala nu exista sarcini precise pentru fiecare dintre ele, lucrurile in acest domeniu fiind noi sau in curs de formare.
In ceea ce priveste siguranta in functionare a unui sistem distribuit, se poate spune ca acesta este mai sigur decat un sistem de operare centralizat. Intr-adevar, caderea unui procesor dintr-un sistem centralizat duce la caderea intregului sistem, pe cand intr-un sistem distribuit procesoarele care dispar pot fi suplinite de celelalte procesoare. Punctul critic al sigurantei de functionare in sistemele distribuite este siguranta retelei de interconectare. Se pot pierde mesaje si, in cazul supraincarcarii retelei de interconectare, performantele scad foarte mult.
4.1. Structura unui SO distribuit
In sistemele de operare distribuite se folosesc transferuri de mesaje prin intermediul celor doua primitive de transfer de mesaje send si receive , primitive care au fost studiate in capitolul "Comunicare intre procese". Un sistem de operare distribuit (SOD) trebuie sa foloseasca numai aceste primitive. Revine ca sarcina principala gasirea unor modele de comunicare cu ajutorul carora sa se poata implementa un SOD. Principalele modele de comunicare utilizate in prezent sunt:
a) comunicarea client server;
b) apelul de procedura la distanta, RPC(Remote Procedure Call);
c) comunicatia de grup.
4.1.1. Comunicarea client-server
Este un model foarte des aplicat in multe domenii. In sistemele de operare distribuite exista doua tipuri de grupuri de procese cooperante:
-servere, grup de procese ce ofera servicii unor utilizatori;
-clienti, grup de procese care consuma serviciile oferite de servere.
 cerere
cerere
raspuns
Fig. 3. Modelul de comunicare client/server.
Atat procesele server cat si cele client executa acelasi kernel al sistemului de operare, in timp ce procesele server si client sunt executate in spatiul utilizator. Exista procese servere specializate in diferite servicii de : lucru cu fisiere, compilatoare, printare etc. Un proces care face o cerere catre un server pentru a solicita un anumit serviciu devine un proces client. De remarcat ca acelasi proces sau grup de procese pot sa fie, in diferite momente, atat server cat si client.
Avantajul principal al acestui tip de comunicatie este dat de eficienta si simplitatea executiei. Comunicatia are loc fara sa se stabileasca mai inainte o conexiune intre client si server, clientul trimitand o cerere iar serverul raspunzand cu datele solicitate.
Principalul dezavantaj al acestui model este dat de dificultatea de programare, deoarece programatorul trebuie sa apeleze explicit functiile de transfer de mesaje.
Comunicarea prin socluri (sokets) in retelele UNIX ce functioneaza pe sistemul client-server
Soclurile (Sockets) sunt un mecanism de comunicatie intre procese in retelele UNIX introdus de 4.3 BSD ca o extensie sau generalizare a comunicatiei prin "pipes-uri". Pipes-urile faciliteaza comunicatiile intre procesele de pe acelasi sistem in timp ce socketurile faciliteaza comunicarea intre procese de pe sisteme diferite sau de pe acelasi sistem.
Proces client
Proces server
Nivelul soclurilor
Nivelul soclurilor
Nivelul protocoalelor TCP si IP
Nivelul protocoalelor TCP si IP
Nivelul driverelor
Nivelul driverelor
![]()
![]()
Retea
Fig. 4. Implementarea comunicatiei prin socluri.
Acest subsistem contine trei parti:
-nivelul soclurilor, care furnizeaza interfata dintre apelurile sistem si nivelurile inferioare;
-nivelul protocoalelor, care contine modulele utilizate pentru comunicatie (TCP si IP);
-nivelul driverelor, care contine dispozitivele pentru conectare in retea.
Comunicarea intre procese prin socluri utilizeaza modelul client server. Un proces server ("listener") asculta pe un soclu (un capat al liniei de comunicatie intre procese) iar un proces client comunica cu serverul la celalalt capat al liniei de comunicatie , pe un alt soclu care poate fi situat si pe alt nod. Nucleul sistemului de operare memoreaza date despre linia de comunicatie deschisa intre cele doua procese.
Exemplu de sistem distribuit bazat pe modelul client-server
Sistemul din acest exemplu (fig. 5.) are un client, care este procesul aplicatie, si cateva servere care ofera diferite servicii.
NOD 1
NOD 2
![]() Proces
aplicatii
Proces
aplicatii
Server de tranzactii
![]() Server
Server
de
comunicatie
Server
de
comunicatie
Server de tranzactii
Server de nume
Server de nume
Server de recuperare
Server de recuperare
Server de obiecte
Server de obiecte
Fig. 5. Exemplu de structura a unui sistem de operare distribuit.
Acest sistem distribuit bazat pe modelul client-server are sase componente dintre care doua sunt programabile de catre utilizatori.
1) Serverul de comunicatie este un singur proces in fiecare nod, rolul sau fiind de a asigura comunicarea aplicatiilor de pe acel nod cu restul sistemului. El asigura independenta aplicatiilor fata de localizarea serverelor de obiecte. Pentru a determina localizarea unui obiect in retea, serverul de comunicatie interogheaza serverul de nume local.
2) Serverul de nume are rolul de a memora si determina plasarea managerilor de obiecte din retea. Exista un singur server de nume in fiecare nod.
3) Serverul tranzactiilor are rolul de a receptiona si trata toate apelurile de Inceputtranzactie , Sfarsittranzactie si Terminareanormalatranzactie. Acest server coordoneaza protocolul pentru tranzactiile distribuite. Exista un singur server de acest fel in fiecare nod.
4) Serverul de obiecte contine module programabile de utilizator, pe baza unor functii de baza livrate de biblioteca de functii. Are rolul de a implementa operatiile asupra obiectelor partajate si de a rezolva concurenta la nivelul obiectelor. Pot exista oricate servere de obiecte in fiecare nod.
5)Serverele de recuperare asigura, recuperarea tranzactiilor cu Terminareanormala, Sabotate Voluntar de procesul de aplicatii sau involuntar la caderea unui nod. Exista cate un server pentru fiecare obiect.
6) Procesele aplicatii sunt scrise de utilizator.
4.1.2. Apelul de proceduri la distanta RPC (Remote Procedure Call)
Ideea acestui mecanism de comunicatie este ca un program sa apeleze proceduri care isi au locul in alte calculatoare.
Se incearca ca apelul unei proceduri la distanta sa semene foarte mult cu apelul unei proceduri locale, la fel ca in limbajele de nivel inalt studiate.
In momentul in care un proces aflat in procesorul 1 apeleaza o procedura din procesorul 2, procesul apelant este suspendat din procesorul 1 si executia sa continua in procesorul 2. Informatia este transferata de la procesul apelant la procedura apelata prin intermediul parametrilor de apel iar procedura va returna procesului apelant rezultatul executiei, la fel ca in cazul unei proceduri locale. In tot acest mecanism, transferurile de mesaje nu sunt vizibile pentru programator. Intr-un astfel de mecanism nu pot fi folositi decat parametri de valoare, parametrii de referinta neputand fi utilizati datorita acheselor diferite ale memoriei locale, aici neexistand o memorie comuna.
RPC este o tehnica destul de des utilizata in sistemele de operare distribuite, chiar daca mai exista probleme atunci cand un calculator se blocheaza sau cand exista modalitati diferite de reprezentare a datelor pe diferite calculatoare.
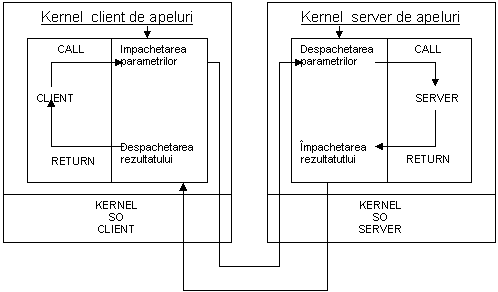
Fig. 6. Schema de principiu a functionarii RPC.
Pasii executati la apelul unei proceduri la distanta pot fi prezentati astfel:
a) Procedura client apeleaza local kernelul client de apeluri, transferandu-i parametrii.
b) Kernelul client de apeluri impacheteaza parametrii primiti, construieste un mesaj pe care il preda kernelului SO client.
c) Kernelul SO client transmite mesajul catre kernelul SO server si de aici spre kernelul server de apeluri.
d) Kernelul server de apeluri despacheteaza parametrii si apeleaza procedura server.
e) Serverul executa functia si returneaza rezultatul kernelului server de apeluri.
f) Kernelul server de apeluri impacheteaza rezultatul, construieste mesajul pe care il preda kernelului SO server.
g) Kernelul SO server transmite mesajul kernelului client de apeluri.
h) Kernelul client de apeluri despacheteaza rezultatul si-l returneaza procedurii client apelante.
In comunicarea RPC, asa cum am prezentat-o mai sus, se leaga un singur client de un singur server. Aceasta comunicare este de tip sincron.
In ultima vreme se utilizeaza protocoale de tip RPC asincron in care se poate ca un client sa comunice cu mai multe servere simultan.
Mecanismele RPC au fost standardizate de OSF (Open Software Foundation). Exista doua mecanisme RPC mai cunoscute:
NCS, dezvoltat de firma Hewlett Packard;
ONC(Open Network Computing)dezvolat de firma Scan.
Consortiul DEC (Distributed Environement Corporation) a lansat de asemenea un RPC pe platforma Microsoft.
RMI (Remote Method Invocation) este un apel la distanta de tip RPC dar folsind obiectele in sistemele Java.
OSF DCE este un pachet de specificatii (Application Environement Specification, AES) ale serviciilor utilizabile de catre o aplicatie client-server intr-un mediu distribuit si eterogen. Odata cu specificatiile DCE,OSF a realizat si un set de produse program care implementeaza aceste servicii, faciliteaza administrarea lor si simplifica elaborarea, testarea si instalarea aplicatiilor care le utilizeaza. Fiecare producator are libertatea de a utiliza si adapta produse OSF sau de a tine la propria sa implementare.
8.4.1.3. Comunicatia de grup
Principalul dezavantaj al mecanismului de comunicare RPC este ca implica o comunicatie unu la unu, adica un singur client cu un singur server. Pentru ca mai multi clienti sa comunice cu un server, s-a introdus un nou tip de mecanism de comunicatie numit comunicatie de grup.
Un grup de comunicatie inseamna o multime de procese care se executa intr-un sistem distribuit, care au proprietatea ca, atunci cand se transmite un mesaj grupului, toate procesele din grup le receptioneaza. Este un tip de comunicatie unu la multi.
Grupurile pot fi clasificate dupa mai multe criterii .
a) In functie de procesele care au dreptul de a transmite un mesaj in interiorul grupului, pot fi:
-grupuri inchise, in care numai procesele membre ale grupului pot transmite un mesaj;
-grupuri deschise, in care orice proces poate transmite un mesaj membrilor grupului.
b)In functie de drepturile de coordonare a operatiilor in grup, sunt:
-grupuri omogene, in care toate procesele au drepturi egale, nici unul dintre ele nu are drepturi suplimentare si toate deciziile se iau in comun;
-grupuri ierarhice, in care unul sau mai multe procese au rolul de coordonator, iar celelalte sunt procese executante.
c) In functie de admiterea de noi membri in grup, exista:
-grupuri statice, care isi pastreaza neschimbate dimensiunea si componentii de la creare si pana la disparitie; dupa crearea unui grup static nici un proces membru nu poate sa paraseasca grupul;
-grupuri dinamice, la care se pot atasa procese membre noi sau altele pot parasi grupul.
d)In functie de modul de gestionare, pot exista:
-grupuri centralizate, in care un proces, numit server, executa toate operatiile referitoare la crearea grupurilor, atasarea de noi procese, parasirea grupului de unele procese etc.; serverul de grup mentine o baza de date a grupurilor, cu membrii fiecarui grup; dezavantajul este ca daca serverul se distruge, toate grupurile isi inceteaza activitatile;
-grupuri distribuite, in care fiecare proces este raspunzator pentru atasarea sau parasirea unui grup; cand un proces se distruge, el nu mai poate anunta grupul de parasirea sa si trebuie ca celelalte procese sa descopere acest lucru.
Pentru implementarea comunicatiei intre grupuri, sistemele de operare pun la dispozitie primitive de gestionare a grupurilor.
O posibilitate mult mai des folosita este aceea de a utiliza biblioteci de comunicatie care suporta comunicatia de grup. Doua dintre cele mai cunoscute astfel de biblioteci sunt:
-PVM(Parallel Virtual Machine);
-MPI(Message Passing Interface).
Biblioteca PVM
PVM (Parallel Virtual Machine) este un pachet de programe dezvoltat de Oak Ridge National Laboratory, Universitatea Statului Tenessee si de Universitatea Emory. Proiectul PMV a fost conceput de Vaidy Sunderam si Al. Geert de la Oak Ridge National Laboratory.
PVM asigura un mediu de lucru unitar in care programele paralele pot fi dezvoltate eficient utilizand un mediu hardware deja existent. Se asigura o transparenta in rutarea mesajelor prin retea, in conversia datelor si in planificarea taskurilor.
In PVM, utilizatorul va scrie aplicatiile ca o colectie de taskuri care coopereaza. Aceste taskuri vor accesa resursele PVM cu ajutorul unor biblioteci de rutine de interfata. Rutinele din cadrul bibliotecilor asigura initierea si terminarea taskurilor, comunicarea si sincronizarea lor. In orice punct al executiei unei aplicatii concurente, orice task in executie poate initia sau termina alte taskuri, poate adauga sau elimina calculatoare din masina virtuala. Utilizatorii pot scrie programe in Fortran sau C, folosind rutine din PVM. Modelul de programe utilizat este cel cu transfer de mesaje. Sunt incluse facilitati de asigurare a tolerantei la defecte.
Descrierea sistemului PVM
Sistemul PVM are doua componente:
-demonul pvmd;
-biblioteca de rutine PVM.
Demonul pvmd trebuie sa existe pe toate masinile care alcatuiesc masina virtuala. Acest demon a fost proiectat astfel incat orice utilizator sa-l poata instala pe orice masina daca dispune de un login valid. Cand un utilizator doreste sa ruleze o aplicatie PVM, va trebui sa creeze masina si apoi sa o porneasca. O aplicatie PVM poate fi pornita de pe orice calculator. Mai multi utilizatori pot configura masini virtuale care se pot suprapune si fiecare utilizator poate executa cateva aplicatii PVM simultan.
Biblioteca de rutine PVM contine un set complet de primitive care sunt necesare pentru cooperare intre tastaturi. Exista urmatoarele tipuri de rutine:
-rutine de trimitere si receptionare a mesajelor;
-rutine de initiere a tastaturilor;
-rutine de coordonare a tastaturilor;
-rutine de coordonare a masinii virtuale.
Modelul de calcul utilizat se bazeaza pe faptul ca o aplicatie este alcatuita din mai multe taskuri, fiecare task fiind responsabil pentru calculul unei parti a problemei.
O aplicatie poate accesa resursele de calcul in trei moduri diferite:
-modul transparent, in care taskurile sunt plasate in sistem prin masina cea mai potrivita;
-modul dependent de arhitectura, in care utilizatorul poate indica o arhitectura specifica pe care un task poate fi executat;
-modul cu specificare a masinii, in care utilizatorul poate indica o anume masina pe care sa se execute un task.
Toate taskurile sunt identificate cu un intreg numit task identifier (TID), echivalent PID-ului din sistemele de operare. Aceste TID-uri trebuie sa fie unice in cadrul masinii virtuale si sunt asigurate de demonul pvmd local. PVM contine rutine care returneaza valoarea TID astfel incat aplicatiile pot identifica taskurile din sistem. Pentru a programa o aplicatie, un programator va scrie unul sau mai multe programe secventiale in C, C++, Fortran++, cu apeluri la rutinele din bibliotecile PVM.
Pentru a executa o aplicatie, un utilizator initiaza o copie a unui task, numit task master iar acesta va initia taskuri PVM care pot fi rulate pe alte masini sau pe aceeasi masina cu task masterul. Acesta este cazul cel mai des intalnit, dar exista situatii in care mai multe taskuri sunt initiate de utilizator si ele pot initia la randul lor alte taskuri.
Consola PVM
Consola PVM este un task de sine statator care permite utilizatorului sa porneasca, sa interogheze si sa modifice masina virtuala. Consola poate fi pornita si oprita de mai multe ori pe orice gazda din PVM, fara a afecta rularea PVM sau a altor aplicatii. La pornire, consola PVM determina daca aceasta ruleaza ; daca nu, se executa pvmd pe aceasta gazda. Prompterul consolei este pvm> .
Comenzile ce se pot aplica pe acest prompter sunt:
add
adauga gazde la masina virtuala;
conf
afiseaza configuratia masinii virtuale;
(numele gazdei, pvmd tid, tipul
arhitecturii si viteza relativa);
,elimina gazde din masina virtuala;
halt
,termina toate procesele PVM, inclusiv
consola si opreste masina virtuala;
id
,afiseaza identificatorul de task al
consolei;
jobs
,afiseaza lista taskurilor in executie;
kill
,termina un task PVM;
mstat
,afiseaza starea gazdelor specificate;
pstat
,afiseaza starea unui task specificat;
quit
,paraseste consola lasand demonii si
taskurile in executie;
reset
,termina toate procesele PVM
exceptand consola;
spawn
,porneste o aplicatie PVM.
PVM permite utilizarea mai multor console. Este posibil sa se ruleze o consola pe orice gazda din masina virtuala si chiar mai multe console in cadrul aceleiasi masini.
Implementarea PVM
Pentru implementarea PVM s-a tinut cont de trei obiective:
-masina virtuala sa cuprinda sute de gazde si mii de taskuri;
-sistemul sa fie portabil pe orice masini UNIX;
-sistemul sa permita construirea aplicatiilor tolerante aplicatiilor tolerante la defecte.
S-a presupus ca sunt disponibile socluri pentru comunicatie intre procese si ca fiecare gazda din masina virtuala se poate conecta direct la celelalte gazde, utilizand protocoale IP(TCB UDP). Un pachet trimis de un pvmd ajunge intr-un singur pas la alt pvmd. Fiecare task al masinii virtuale este marcat printr-un identificator de task (TID) unic. Demonul pvmd asigura un punct de contact cu exteriorul pentru fiecare gazda. Pvmd este de fapt un router care asigura controlul proceselor si detectia erorilor. Primul pvmd, pornit de utilizator, este denumit pvmd master, ceilalti, creati de master, sunt denumiti slave. In timpul operarii normale, toti pvmd sunt considerati egali.
Toleranta la defecte este asigurata in felul urmator:
-daca masterul a pierdut contactul cu un slave, il va marca si il va elimina din masina virtuala;
-daca un slave pierde contactul cu masterul, atunci el se elimina singur din masina.
Structurile de date importante pentru pvmd sunt tabele de gazde care descriu configuratia masinii virtuale si taskurile care ruleaza in cadrul acesteia.
Exista urmatoarele biblioteci:
-biblioteca PVM (lib pvm);
-comunicatiile PVM.
Biblioteca PVM contine o colectie de functii care asigura interfatarea taskurilor cu pvmd si cu alte taskuri, functii pentru impachetarea si despachetarea mesajelor si unele functii PVM de sistem. Aceasta biblioteca este scrisa in C si este dependenra de sistemul de operare si de masina.
Comunicatiile PVM se bazeaza pe protocoalele de Internet IP (TCP si UDP) pentru a se asigura de portabilitatea sistemului.
Protocoalele IP faciliteaza rutarea prin masini tip poarta intermediara. Rolul sau este de a permite transmiterea datelor la masini ce nu sunt conectate direct la aceiasi retea fizica. Unitatea de transport se numeste datagrama IP. La acest nivel se folosesc adrese IP care sunt formate din doua parti:
- prima parte identifica o retea si este folosita pentru rutarea datagramei;
- a doua parte identifica o conexiune la un anumit dat in interiorul retelei respective.
Serviciul de livrare asigurat de IP este de tipul fara conexiune, fiecare datagrama fiind rutata prin retea independent de celelalte datagrame.
UNIX foloseste doua protocoale de transport:
-UDP (User Datagram Protocol), un proptocol fara conexiune;
-TCP (Transmission Control Protocol), orientat pe conexiune; caracteristicile TCP-ului constau in transmiterea adresei destinatiei o singura data la stabilirea conexiunii, garantarea odinei datelor transmise si bidirectionalitatea.
In sistemele PVM sunt posibile trei tipuri de comunicatii:
-intre demonii pvmd;
-intre pvmd si taskurile asociate;
-intre taskuri.
a) Comunicatia pvmd-pvmd
Demonii pvmd comunica intre ei prin socluri UDP. Pachetele vor avea nevoie de mecanisme de confirmare si directare UDP. Se impun, de asemenea, limitari in ceea ce priveste lungimea pachetelor, ajungandu-se la fragmentarea mesajelor lungi. Nu s-a utilizat TCP din trei motive:
- o masina virtuala compusa din n masini necsita n(n-1)/2 conexiuni, un numar care ar fi greu de stabilit;
-protocolul TCP nu poate sesiza caderea unei gazde pvmd;
-protocolul TCP limiteaza numarul fisierelor deschise.
b) Comunicatia pvmd-task
Un task comunica cu un pvmd caruia ii este asociat prin intermediul conexiunilor. Taskul si pvmd mentin o structura FIFO de pachete, comutand intre citire si scriere pe conexiuni TCP. Un dezavantaj al acestui tip de conectare este numarul crescut de apeluri sistem necesare pentru a transfera un pachet intre un task si un pvmd.
c) Comunicatie task-task
Comunicatiile intre taskurile locale se realizeaza ca si comunicatiile pvmd-task. In mod normal, un pvmd nu comunica cu taskurile de pe alte gazde. Astfel, comunicatiile ce trebuie realizate intre taskuri de pe gazde diferite vor folosi ca suport comunicatiile pvmd.
Limitari ale resurselor
Limitarile resurselor impuse de sistemul de operare si de hardul disponibil se vor reflecta in aplicatiile PVM. Cateva din limitari sunt afectate dinamic datorita competitiei dintre utilizatorii de pe aceiasi gazda sau din retea. Numarul de taskuri pe care un pvmd le poate deservi este limitat de doi factori:
- numarul permis unui utilizator de catre sistemul de operare;
- numarul de descriptori de fisiere disponibili pentru pvmd.
Marimea maxima a mesajelor PVM este limitata de marimea memoriei disponibile pentru un task.
Aceste probleme vor fi evitate prin revizuirea codului aplicatiei, de exemplu prin utilizarea mesalejor cat mai scurte, eliminarea strangularilor si procesarea mesajelor in ordinea in care au fost generate.
Programarea in PVM
Lansarea masinii virtuale PVM se face prin lansarea in executie a procesului server master, folosind functia
pvm-start-pvmd .
Apoi se lanseaza functia
pvm-setopt
in care se seteaza diferitele optiuni de comunicatie.
Pe procesorul server master trebuie sa fie un fisier de descriere a configuratiei masinii si anume fisierul
h.stfile .
Acesta contine numele statiilor pe care se configureaza masina virtuala, caile unde se afla fisierele executabile, caile unde se afla procesele server (demonii) de pe fiecare statie, codul utilizatorului si parola.
Configuratia masinii virtuale este dinamica; statii noi in retea pot fi adaugate prin apelul functiei
pvm-addh.sts
Alte statii pot fi excluse prin functia
pvm-delh.sts
Functionarea masinii se opreste prin
pvm-halt
Controlul proceselor.
Pentru atasarea unui proces la masina virtuala PVM se apeleaza functia
pvm-mytid
Prin aceasta functie se inroleaza procesul si se returneaza identificatorul de task TID.
Crearea dinamica de procese noi in masina virtuala se face prin apelul functiei
pvm-spawn
La apelul functiei de mai sus se specifica adresa statiei unde vor fi create procesele noi, chiar PVM-ul putand selecta statiile unde vor fi create si lansate procesele noi. De exemplu:
numt=pvm-spawn("my-task",NULL,pvmtaskdefault,0,n-task,tids);
Se solicita crearea a n-task procese care sa execute programul my-task pe statiile din PVM. Numarul real de procese create este returnat de functia numt. Identificatorul fiecarui task creat este depus intr-un element al vectorului tids.
Un proces membru al masinii PVM poate parasi configuratia prin apelul
pvm-exit
sau poate fi terminat de catre un alt proces care apeleaza functia
pvm-kill(tid)
Interfata PVM suporta doua modele de programare diferite si pentru fiecare din acestea se stabilesc conditiile de mediu de executie . Aceste modele sunt SPMD(Single Program Multiple Data) si MPMD (Multiple Program Multiple Data).
In modelul SPMD, n instante ale aceluiasi program sunt lansate cu n taskuri ale unei aplicatii paralel, folosind comanda spwan de la consola PVM, sau, normal, in cele n statii simultan. Nici un alt task nu este creat dinamic de catre taskurile aflate in executie, adica nu se apeleaza functia pvm-spwan. In acest model initializarea mediului de programare consta in specificarea statiilor pe care se executa cele n taskuri.
In modelul MPMD, unul sau mai multe taskuri distincte sunt lansate in diferitele statii si acestea creeaza dinamic alte taskuri.
Comunicatiile in masina virtuala PVM
In masina virtuala PVM exista doua tipuri de mesaje intre procesele componente :
- comunicatie punct la punct, adica transferul de mesaje intre doua procese;
-comunicatie colectiva, adica difuziunea sau acumulare de mesaje intr-un grup de procese.
Comunicatia punct la punct.
Pentru transmiterea unui mesaj de catre un proces A la un mesaj B, procesul transmitator A initializeaza mai intai bufferul de transmisie prin apelul functiei de initializare:
int pvm-init send(int encode);
Argumentul (encode) stabileste tipul de codare al datelor in buffer. Valoarea returnata este un identificator al bufferului curent de transmisie in care se depun datele impachetate, folosind functia
pvm-pack
Dupa ce datele au fost depuse in bufferul de transmisie, mesajul este transmis prin apelul functiei
int pvm-send(int tid,int msgtag);
Functia de transmisie este blocanta. Ea returneaza controlul procesului apelant numai dupa ce a terminat de transmis mesajul. Argumentul tid este identificatorul procesului receptor iar flagul msgtag este folosit pentru a comunica receptorului o informatie de tip mesaj pe baza careia receptorul ia decizia acceptarii mesajului si a tipului de prelucrari pe care trebuie sa le faca asupra datelor din mesaj. Valoarea returnata de functia pvm-send este
0, transmisie corecta
-1, in cazul aparitiei unei erori
Pentru receptia unui mesaj, procesul receptor apeleaza functia
int pvm-recv(int tid,int msgtag);
Aceasta functie este blocanta. Ea returneaza controlul procesului apelant numai dupa terminarea executiei, deci dupa receptia mesajului. Argumentul tid specifica identificatorul procesului de la care se asteapta mesajul iar argumentul msgtag specifica ce tip de mesaj este asteptat. Receptia se efectueaza numai pentru mesajele care corespund celor doua argumente sau pentru orice transmitator, daca tid=-1, si orice tip de mesaj, daca msgtag=-1.
Valoarea returnata este identificatorul bufferului de receptie in care au fost depuse datele receptionate. Din acest buffer datele sunt extrase folosind functia de despachetare a datelor
pvm-unpack
In biblioteca PVM exista si o functie de receptie neblocanta
pvm-nrecv
Aceasta returneaza controlul procesului apelant imediat, fara ca acesta sa astepte daca mesajul a fost receptionat.
Comunicatia colectiva in PVM
In sistemul PVM se pot crea grupuri dinamice de procese care executa sarcini corelate, comunica si se sincronizeazi intre ele. Un proces se poate atasa unui grup, definit printr-un nume unic in masina virtuala PVM, prin apelul functiei
int pvm-joingrup(cher*group-name);
Daca grupul cu numele group-name nu exista, el este creat. Valoarea returnata este un identificator al instantei procesului in grupul respectiv, care se adauga identificatorului procesului. Acest identificator este 0 pentru procesul care creeaza grupul si are cea mai mica valoare disponibila in grup pentru fiecare proces care apeleaza functia pvm-joingroup.
Un proces poate apartine simultan unuia sau mai multor grupuri din masina virtuala. El poate parasi un grup prin apelul functiei
int pvm-lvgroup(cher*group.name);
Daca un proces paraseste un grup, fara ca un altul sa-l inlocuiasca , pot aparea goluri in identificatorii de instanta de grup ai proceselor ramase.
Un proces poate obtine diferite informatii de grup. Functiile pvm-getinst, pvm-gettid, pvm-gsize returneaza identificatorul procesului in grup.
Comunicatia colectiva in masina virtuala PVM se desfasoara intre procesele membre ale unui grup. Functiile de comunicatie colectiva sunt:
-Functii de difuziune
int pvm-bcast(cher*group-name, int msgtag);
Se difuzeaza asincron mesajul aflat in bufferul de transmisie curent al procesului apelant cu flagul de identificare msgtag , catre toate procesele membre ale grupului cu nume group-name. Procesul apelant poate fi sau nu membru al grupului. Daca este membru, nu se mai transmite msg lui insusi.
-Functia de distribuire
int pvm-scatter(void*my array,void*s-array,
int dim, int type,int msgtag,
cher*group-name,int root);
Un vector de date de tipul type, cu multe s-array si de dimensiune dim, aflat in spatiul de adresa al procesului radacina, este distribuit uniform tuturor proceselor din grupul cu numele group-name. Fiecare proces din grup trebuie sa apeleze functia pvm-scatter si fiecare receptioneaza o partitie a datelor din vectorul s-array din procesul radacina (cu identificatorul root), in vectorul local s-array.
Functia de colectare
int pvm-gather(void*g-array,void*myarray,
int dim,int type,cher*group-name,
int root);
Se colecteaza toate mesajele cu flagul de identificare msgtag de la toate procesele membre ale grupului cu nume group-name in procesul radacina cu identificatorul root. Colectarea are loc in vectorul de date g-array, a datelor aflate in fiecare proces in vectorii cu numele group-name in procesul radacina (definit de utilizator) cu identificatorul root.
Functia de reducere
int pvm reduce(int operation,void*myrols,int dim,
int type,int msgtag,cher*groupe-name,
int root);
Se efectueaza operatia de reducere paralela intre toate procesele membre ale unui grup. Argumentul operation defineste operatia de reducere. Fiecare proces efectueaza mai intai operatia de reducere a datelor din vectorul local de date, de tipul type , cu numele myrols, de dimensiune dim. Valoarea rezultata este transferata procesului radacina root in care se va afla valoarea de reducere finala.
Functia de sincronizare intr procesele membre
int pvm-barrier(cher*group name, int ntasks);
La apelul acestei functii procesul este blocat pana cand un numar ntasks procese din grupul cu numele group-name au apelat functia pvm-barrier.
Exemple de programare in PVM
Program de reducere paralela
Am vazut in programarea paralela (pe multiprocesoare) cum se realizeaza operatia de reducere cand avem la dispozitie o memorie comuna. Sa vedem acum cum se face aceasta operatie prin transfer de mesaje in pvm.
#include"pvm3.h"
#define NTASKS 4
int main()
/*se introduce o bariera pana ce NTASKS procese s-au alaturat grupului*/
pvm-feeze group("summex",NTASKS);
/*Apelul functiei de comunicatie colectiva pentru calculul sumei unui grup*/
pvm-reduce(pvm sum,&sum,1,
pvm-INT,1,"summex",0);
/*Procesul 0 tipareste rezultatul operatiei de reducere*/
if(groupid==0) print("sum=%dn",sum");
/*Sincronizare pentru ca toate procesele sa execute operatia inainte de parasirea grupului si terminarea programului*/
pvm-barrier("summex",NTASKS))
pvm-evgroup("summex");
pvm -exit();
Reducerea paralela se executa pe un numar de procese (taskuri) definit prin constanta NTASKS care se alege in functie de numarul de statii din retea. Fiecare proces incepe executia prin obtinerea propriului identificator de task PVM (mytid). Apoi procesul se ataseaza grupului cu numele "summex" si obtine la atasare identificatorul de instanta de grup (groupid). Procesul master are groupid=0 si creeaza NTASKS-1 procese. Deoarece operatia de reducere paralela nu poate incepe pana cand grupul nu este complet creat, se introduce un punct de sincronizare prin functia pvm-freeze group. Aceasta functie opreste cresterea numarului de procese din grupul cu numele group-name la valoarea size, transformand grupul intr-un grup static. Ea are si rolul de sincronizarea si trebuie sa fie apelata inainte de executia unor operatii colective intr-un grup., deoarece o astfel de operatie, odata inceputa, poate fi perturbata de aparitia unui nou membru in grup. In fiecare proces se executa reducerea intr-un vector cu lungimea 1. In variabila sum fiecare proces memoreaza identificatorul sau (mytid) .Dupa executia reducerii paralele, suma tuturor identificatorilor taskurilor din grup este afisata la consola de catre procesul master. Pentru ca ici un proces sa nu poata parasi grupul inainte ca toate procesele grupului sa fi terminat operatiile, se introduce un nou punct de sincronizare, prin apelul functiei pvm-barrier, dupa care programul poate fi terminat prin desfiintarea grupului. Toate procesele sunt detasate din grup prin functia pvm-lv group si parasesc masina virtuala prin pvm-exit.
Biblioteca MPI (Massage Passing Interface)
MPI este o biblioteca standard pentru construirea programelor paralele, portabile in aplicatii C si Fortran++, care poate fi utilizata in situatii in care programulpoate fi partitionat static intr-un numar fix de procese.
Cea mai mare diferenta intre biblioteca MPI si cea PVM este faptul ca grupurile de comunicatie MPI sunt grupuri statice. Dimensiunea grupului este statica si este stabilita la cererea grupului. In acest fel proiectarea si implementarea algoritmilor paraleli se face mai simplu si cu un cost redus.
Functiile din MPI sunt asemanatoare cu cele din PVM. Desi MPI are peste 190 de functii, cele mai des folosite sunt:
MPI-Init()/*initializeaza biblioteca MPI*/
PMI-Finalize /*inchide biblioteca MPI*/
MPI-Comm-SIZE /*determina numarul proceselor
in comunicator*/
MPI-Comm-rank() /*determina rangul procesului
in cadrul grupului*/
MPI-send() /*trimite un mesaj*/
MPI-recv() /*primeste un mesaj*/
Iata mai jos programul de reducere, pe care l-am prezentat in PVM, implementat in MPI.
#include<mpi.h>
#include<sys/types.h>
#include<stdio.h>
int main()
Definirea mediului de programare paralela in sistemul MPI se face prin executia unui program de initializare care stabileste procesoarele ce vor rula in MPI. In MPI toate procesele unei aplicatii se creeaza la initializarea acesteia. In cursul executiei unei aplicatii nu pot fi create procese dinamice si nu poate fi modificata configuratia hardware utilizata.
Comunicatii, grupuri si contexte in MPI
Comunicatorul specifica un grup de procese care vor coordona operatii de comunicare, fara sa afecteze sau sa fie afectat de operatiile din alte grupuri de comunicare.
Grupul reprezinta o colectie de procese. Fiecare proces are un rang in grup, rangul luand valori de la 0 la n-1. Un proces poate apartine mai multor grupuri, caz in care rangul dintr-un grup poate fi total diferit de rangul in alt grup.
Contextul reprezinta un mecanism intern prin care comunicatorul garanteaza grupului un spatiu sigur de comunicare.
La pornirea unui program, sunt definiti doi comunicatori impliciti:
MPI-COMM-WORLD , care are ca grup de procese toate procesele din job;
MPI-COMM-SELF, care se creeaza pentru fiecare proces, fiecare avand rangul 0 in propriul comunicator.
Comunicatorii sunt de doua feluri:
-intracomunicatori, care coordoneaza operatii in interiorul unui grup;
-extracomunicatori, care coordoneaza operatii intre doua grupuri de procese.
Lansarea in executie se poate face in doua medii:
CRE (Cluster Tools Runtime Environement)
LSF (Lood Sharing Facility)
In mediul CRE exista patru comenzi care realizeaza functii de baza.
mprun/*executa programe MPI*/
mpkill /*termina programele*/
mpps /*afiseaza informatii despre
programele lansate*/
mpinfo /*afiseaza informatii despre noduri*/
8.4.2. Exemple de sisteme de operare distribuite
4.2.1. Sistemul de operare AMOEBA
Sistemul de operare AMOEBA a fost creat de profesorul Andrew Tanenbaum la Vrije Universiteit Amsterdam. S-au urmarit doua scopuri:
-crearea unui sistem de operare distribuit care sa gestioneze mai multe calculatoare interconectate intr-un mod transparent pentru utilizator, astfel incat sa existe iluzia utilizarii unui singur calculator;
-crearea unei platforme pentru dezvoltarea limbajului de programare distribuit ORCA.
AMOEBA ofera programatorilor doua mecanisme de comunicatie:
-comunicatie RPC (Remote Procedure Call);
-comunicatie de grup.
Comunicatia de tip RPC utilizeaza trei primitive:
trans /*un client transmite o cerere
spre server*/
get-request /*severul isi anunta
disponibilitatea*/
put-reply /*serverul comunica rezultatul
unei cereri*/
Comunicatia de grup asigura ca toate procesele din grup sa primeasca aceleasi mesaje si in aceeasi ordine. In AMOEBA exista un proces secventiator care are doua roluri:
- acorda numere de ordine mesajelor care circula in grup;
- pastreaza o istorie a mesajelor si realizeaza, atunci cand este cazul, o retransmisie a mesajelor care nu au fost transmise.
Transmiterea unui mesaj catre grup se face in doua moduri, functie de lungime mesajului:
-se transmite mesajul catre secventiator, acesta ataseaza mesajului un numar de secvente dupa care secventiatorul difuzeaza mesajul catre toate procesele; fiecare mesaj trece de doua ori prin retea;
-se anunta prin difuzare ca se doreste transmiterea unui mesaj iar secventiatorul raspunde prin acordarea unui numar de secvente dupa care procesul care a dorit sa transmita mesajul face difuzarea acestuia; in acest caz se difuzeaza mai multe mesaje, fiecare procesor fiind intrerupt odata pentru mesajul care solicita numarul de secvente si a doua oara pentru mesajul propriu zis.
Procesul care transmite mesajul se blocheaza pana primeste si el mesajul, ca orice proces din grup. Secventiatorul pastreaza o istorie a mesajelor transmise. Procesul anunta secventiatorul numarul de secventa al ultimului mesaj receptionat. Secventiatorul poate, la randul sau, sa ceara situatia mesajelor de la un proces care nu a mai transmis de multa vreme nimic. Utilizand aceste informatii, secventiatorul poate sa isi gestioneze in mod corespunzator istoria.
Structura sistemului de operare AMOEBA
AMOEBA este bazat pe un microkernel care ruleaza pe fiecare procesor in parte, deasupra caruia ruleaza servere ce furnizeaza servicii. Microkernelul asigura gestiunea principalelor resurse ale sistemului ce pot fi grupate in patru categorii.
1)Gestiunea proceselor si threadurilor.
2)Gestiunea de nivel jos a memoriei.
3)Gestiunea pentru comunicatie.
4)Gestiunea operatiilor de intrare/iesire de nivel jos.
1) Procesele reprezinta mecanismul care asigura executia in AMOEBA. Un proces contine un singur spatiu de adrese. Threadurile (firele de executie) sunt interne unui proces si au acces la spatiul de adrese al procesului.
In AMOEBA un procesor nu are proprietar si de aceea utilizatorul nu are nici un fel de control asupra procesoarelor pe care ruleaza aplicatiile. Sistemul de operare ia deciziile plasarii unui proces pe un anumit procesor, in functie de diferiti factori ca: incarcarea procesorului, memoria disponibila, puterea de calcul etc.
Anumite procesoare pot fi dedicate rularii unor servere care cer multe resurse, de exemplu serverul de fisiere.
2)Gestiunea memoriei se face prin segmente de lungime variabila. Acestea sunt pastrate in totalitate in memorie si sunt rezidente in memorie, adica sunt pastrate tot timpul in memorie. Nu se face swapping cu aceste segmente. Din aceasta cauza dimensiunea memoriei trebuie sa fie foarte mare, Tannenbaum considerand resursa memorie ca una ieftina.
Segmentele de memorie pot sa fie mapate in spatiul de adresa al mai multor procese care se executa pe acelasi procesor. In felul acesta se creeaza memorie partajata.
3)Gestiunea comunicatiei se face, asa cum a fost prezentat, prin RPC si comunicatie de grup.
4)Operatiile de intrare/iesire se efectueaza prin intermediul driverelor. Pentru fiecare dispozitiv exista un driver. Acestea apartin microkernelului si nu pot fi adaugate sau sterse dinamic. Comunicatia driverelor cu restul sistemului se face prin RPC. Deoarece s-a ales o solutie cu microkernel, serverele sunt acelea care au preluat sarcina vechiului kernel. Exemple de servere sunt:
-servere de fisiere;
-serverul de boat;
-serverul de executie;
-serverul de TCP/IP;
-serverul de generare a numerelor aleatorii;
-serverul de erori;
-serverul de mail.
Pentru principalele servere exista apeluri de biblioteci cu ajutorul carora un utilizator poate accesa obiecte. Exista un compilator special cu ajutorul caruia se pot crea functii de biblioteca pentru serverele nou create. In AMOEBA toate resursele sunt vazute ca niste obiecte. Acestea sunt entitati ce apar intr-o noua paradigma de programare. Prin definitie, un obiect este o colectie de variabile care sunt legate impreuna de un set de proceduri de acces numite metode. Proceselor nu li se permite accesul direct la aceste variabile ci li se cere sa invoce metode. Un obiect consta dintr-un numar de cuvinte consecutive in memorie (de exemplu in spatiul de adresa virtuala din kernel) si este deci o structura de date in RAM.
Sistemele de operare care utilizeaza obiectele, le construiesc asa fel ca sa furnizeze o interfata uniforma si consistenta cu toate resursele si structurile de date ca procese, threaduri, smafoare etc. Uniformitatea consta in numirea si accesarea in acelasi mod al obiectelor, gestionarea uniforma a partajarii obiectelor intre procese, punerea in comun a controlorilor de securitate, gestionarea corecta a cotelor de resurse etc.
Obiectele au o structura si pot fi tipizate. Structurarea se face prin doua parti principale:
-o parte (header) care contone o anumita informatie comuna tuturor obiectelor de toate tipurile ;
-o parte cu date specifice obiectului.
Obiectele sunt gestionate de servere prin intermediul capabilitatilor. La crearea unui obiect, serverul construieste o capabilitate protejata criptografic pe care o asociaza obiectului. Clientul primeste aceasta capabilitate prin care va accesa obiectul respectiv.
Concluzii.
Principala deficienta a sistemului de operare AMOEBA este ca nu s-a creat o varianta comerciala a lui, din mai multe motive:
-fiind un produs al unui mediu universitar, nu a avut forta economica sa se impuna pe piata IT;
-desi a fost unul dintre primele sisteme de operare distribuite (proiectarea a inceput in anii optzeci) si desi a introdus multe concepte moderne, preluate astazi in majoritatea sistemelor de operare distribuite (microkernelul, obiecte pentru abstractizarea resurselor, RPC, comunicatii de grup), alte firme au introdus rapid alte sisteme de operare.
4.2.2. Sistemul de operare GLOBE
In prezent, profesorul Tanenbaum lucreaza la un nou sistem de operare distribuit, denumit GLOBE, ale carui prime versiuni au aparut deja. Este un sistem de operare, creat pentru aplicatii distribuite pe o arie larga, care utilizeaza obiecte locale sau distribuite. In GLOBE, un obiect este o entitate formata din:
-o colectie de valori ce definesc starea obiectului;
-o colectie de metode ce permit inspectarea si modificarea starii obiectului;
-o colectie de interfete.
Un obiect local este continut in intregime (stare, metode, interfata) intr-un singur spatiu de adresa.
Un obiect distribuit este o colectie de obiecte locale care apartin unor spatii de adrese diferite.
Obiectele locale comunica intre ele pentru a mentine o stare globala consistenta.