|
|
|
|
Elementele modelului relational
Modelul relational a fost fundamentat in 1970 de E.F. Codd si se bazeaza pe teoria matematica a relatiilor si pe calculul relational. Ideea unui model ansamblist a datelor a fost lansata insa in 1968 de catre Childs D.F. care arata ca orice structura de date poate fi reprezentata sub forma de tabele in interiorul carora trebuie sa existe si informatie de legatura [1]
Conform modelului relational datele si relatiile dintre ele sunt organizate sub forma unor tabele constituite din linii si coloane, fiecare reprezentand un element distinct al bazei. Tabelele poseda o independenta fizica totala ceea ce asigura independenta dintre date si prelucrari. Manipularea datelor are loc prin intermediul unui ansamblu de operatori algebrici pentru care relatiile sunt operanzii si rezultatele [2]
Acest model se delimiteaza de celelalte modele prin reguli, cunoscute sub denumirea de normalizare sau forme normale, care aplicate structurii stabilite prin tabele permit definirea optima a continutului lor.
Cea mai mare parte a bazelor de date si a SGBD-urilor comercializate la ora actuala fac apel la concepte si reguli propuse de modelul relational. In plus, pentru a face fata noului context informational si organizational au fost propuse diverse extensii ale acestui model: modele relationale cu valori structurate, modelul relational Fuzzy etc.
Avantajele modelului relational in comparatie cu celelalte tipuri de modele sunt:
independenta sporita a programelor de aplicatie fata de modul de reprezentare interna a datelor si de metodele de acces la date;
definirea unei structuri conceptuale optime, minimalizand redundanta datelor si erorile la actualizare (prin tehnica de normalizare);
utilizarea unor limbaje procedurale bazate pe algebra relationala si a unor limbaje neprocedurale care contribuie la imbunatatirea comunicarii dintre sistem si utilizatorii neinformaticieni;
integritatea si confidentialitatea datelor prin folosirea unor mecanisme proprii;
utilizarea paralelismului in prelucrarea datelor, deoarece manipularea datelor se realizeaza numai la nivel de relatie.
O baza de date relationala poate fi definita ca un ansamblu de tabele aflate in legatura. Fiecare tabel este identificat printr-un un nume propriu avand linii si coloane la intersectia carora se introduc valori atomice.
Structurarea datelor dupa modelul relational impune folosirea urmatoarelor notiuni: domeniu, relatie (tabela), atribut, tuplu (n-tuplu sau n-uplu) si schema relationala [3] Elementele modelului relational sunt prezentate in fig. nr. 5.1.
391
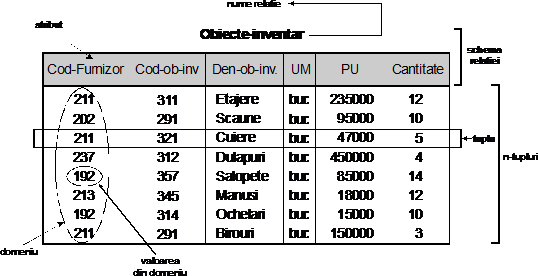
Fig. nr. 5.1. Elementele modelului relational
391
Literatura de specialitate
prezinta mai multe definitii, toate insa exprimand aspectele de
esenta. Prezentam in continuare cateva astfel de abordari.
Domeniul este definit ca ansamblul valorilor acceptate (autorizate) pentru un element component al relatiei(tabelei). [4]
Un domeniu este caracterizat printr-un nume si poate fi definit explicit (in extensie) sau implicit (in intensie). Definirea explicita se realizeaza prin enumerarea tuturor valorilor sale, iar definirea implicita se realizeaza prin precizarea proprietatilor pe care le au valorile din domeniul respectiv.
Exemplu:
definirea in extensie: UNIVERSITATE = ;
definirea in intensie: INTREG, REAL
Doua domenii sunt declarate compatibile daca sunt semantic comparabile, adica daca ansamblurile care le definesc nu sunt disjuncte. Doua domenii identice sau legate prin inclusiune sunt compatibile.
Relatia (tabela) reprezinta un subansamblu al produsului cartezian al unei liste de domenii caracterizat printr-un nume si corespunde unei restrictii semantice din universul real modelat deoarece fiecare obiect din acest univers trebuie sa fie identificat intr-o maniera unica si diferentiat in raport cu alte obiecte.
Atributul reprezinta numele dat unui domeniu dintr-o relatie si determina ansamblul de valori pe care acesta il poate lua. Notiunea de atribut nu trebuie confundata cu cea de domeniu. Intr-o relatie numele atributelor este unic, ceea ce asigura precizarea fara ambiguitate a rolului jucat de fiecare domeniu al relatiei. Orice atribut al unei tabele oarecare trebuie sa fie atomic, adica sa nu mai poata fi descompus in alte atribute.
Tuplul sau n-uplu reprezinta un rand sau o linie distincta de valori din cadrul unei tabele (relatie) rezultand ca o relatie este un ansamblu de tupluri care poate fi definita extensiv (prin indicarea listei tuturor tuplurilor ce o compun) si intensiv (prin indicarea predicatului de apartenenta a unui tuplu la relatia respectiva).
Dintr-un alt punct de vedere o relatie este ansamblul m-tuplurilor de valori definita astfel:
R = ,
unde tk = (dk1 , dk2 ,., dki,., dkn ), iar dk1 este o valoare in D1, d k2 este o valoare in D2 , ., dkn este o valoare in Dn;
in care:
n- reprezinta ordinul lui R;
m- este cardinalitatea lui R.
Rezulta ca numarul tuplurilor dintr-o relatie reprezinta cardinalitatea relatiei, in timp ce numarul valorilor dintr-un tuplu defineste gradul sau ordinul relatiei.
Doua tupluri sunt identice daca si numai daca pentru fiecare domeniu ele au aceeasi valoare.
Ansamblul minimal de atribute prin care se poate identifica in mod unic orice tuplu dintr-o relatie reprezinta cheia relatiei. Orice relatie poseda cel putin o cheie. Cand cheia este constituita dintr-un singur atribut, poarta numele de cheie simpla, iar atunci cand este formata din mai multe atribute ea se numeste cheie compusa.
Cheia primara a unei relatii (tabele) este un atribut sau grup de atribute care identifica fara ambiguitate fiecare tuplu (linie) a relatiei (tabelei) [5]
La alegerea unei chei primare administratorul bazei de date trebuie sa aiba in vedere criterii prin care sa se asigure identificarea efectiva a tuplurilor (lungime, natura) .
Exista trei restrictii pe care trebuie sa le verifice cheia primara:
unicitatea - o cheie identifica un singur tuplu (linie) a relatiei;
compozitia minimala - atunci cand cheia primara este compusa, nici un atribut din cheie nu poate fi eliminat fara distrugerea unicitatii tuplului in cadrul relatiei (in cazuri limita o cheie poate fi alcatuita din toate atributele relatiei);
valorile non-nule - valorile atributului sau ale ansamblului de atribute ce desemneaza cheia primara sunt intotdeauna specificate, deci ne-nule; nici un atribut din compozitia cheii primare nu poate avea valori nule.
Daca intr-o relatie exista mai multe combinatii de atribute care confera unicitate tuplului, acestea sunt denumite chei candidate. Atunci cand o cheie candidata nu este cheie primara este considerata cheie alternativa (secundara).
Legatura intre tuplurile din relatii diferite se realizeaza prin atribute sau combinatii de atribute numite chei straine (externe). Cheile straine (coloanele de referinta) sunt, asadar, atribute sau combinatii de atribute care pun in legatura linii (tupluri) din relatii diferite.
In figura nr. 5.2 sunt prezentate cateva tabele si cheile asociate acestora pentru stabilirea relatiilor dintre ele si pentru identificarea tuplurilor din continutul lor.

Fig. nr. 5.2 Relatii si tipuri de chei
In relatia FURNIZORI:
COD-FURN - cheie primara
NUME-FURNIZOR - cheie alternativa
In relatia FACTURI:
NR-FACTURA - cheie primara
COD-FURN - cheie straina catre relatia FURNIZORI
In relatia NOMEN-OBINV:
COD-OBINV - cheie primara
In relatia OBINV-RECEPT:
NR-FACT si CODOBINV - cheie primara
NR-FACT - cheie straina catre relatia FACTURI
COD-OBINV - cheie straina catre relatia NOMEN-OBINV
Schema relatiei se constituie din numele relatiei urmat de lista atributelor si eventual de definirea domeniului lor[6], fiind posibile mai multe reprezentari. Schema este cunoscuta sub numele de intensia relatiei. Ea este expresia proprietatilor comune si invariante ale tuplurilor care compun relatia. Spre deosebire de intensie, extensia unei relatii reprezinta ansamblul tuplurilor care compun la un moment dat relatia si este variabila in timp.
Extensia unei relatii (continutul propriu-zis) este stocata fizic de obicei in spatiul asociat bazei de date relationale, este definita explicit si poarta numele de relatie de baza. Daca nu este memorata in baza de date (cazul asa-numitelor relatii virtuale) ea poarta numele de relatii derivate sau viziuni, necesitand precizarea unei expresii relationale care este evaluata la stabilirea efectiva a tuplurilor care compun acest tip de relatie.
Schema relationala este un ansamblu de relatii semantic legate prin domeniul lor de definire sau prin reguli de integritate.
Conceptul de relatie permite pe de o parte reprezentarea unei entitati din universul modelat si o legatura semantica inter-entitate. Intr-o entitate, fiecarei legaturi semantice ii corespunde o relatie. In teoria sistemelor, adaugarea unui nou tuplu determina modificarea fizica a relatiei, in timp ce din punct de vedere semantic, aceasta ramane neschimbata. Pentru definirea, fara ambiguitati semantice, a unei relatii nu este suficienta notiunea de domeniu.
Regulile de integritate constituie un anumit numar de controale care ar trebui sa fie satisfacute de catre datele bazei, pentru a putea fi considerate coerente si concrete in raport cu lumea reala pe care o reflecta[7]
Modelul relational se bazeaza pe urmatoarele restrictii minimale: unicitatea cheii, restrictia referentiala si restrictia de entitate.
Unicitatea cheii. Ansamblul minim de
atribute a carui cunoastere permite identificarea unui n-uplet unic
al relatiei se numeste cheie. Conform acestei reguli intr-o
relatie R care are cheia K, oricare ar fi tuplurile t1 si t2 trebuie
satisfacuta inegalitatea: t1(K) ![]() t2(K). Altfel spus,
doua n-upluri nu pot avea aceeasi valoare pentru atributul cheie.
t2(K). Altfel spus,
doua n-upluri nu pot avea aceeasi valoare pentru atributul cheie.
Restrictia referentiala (integritatea referirii). Daca un acelasi atribut apare intr-o relatie ca cheie si intr-o alta relatie ca non-cheie, orice valoare a atributului non-cheie trebuie sa existe in atributul cheie[8]. Respectand aceasta regula intr-o relatie R1, care refera o relatie R2, valorile cheii externe trebuie sa figureze printre valorile cheii primare din relatia R2, sau sa fie valori nedefinite "null".
Consideram pentru exemplificare urmatoarele trei relatii: STUDENT, SIT.SC si EXAMEN. Restrictiile referentiale sunt ilustrate in figura 5.3.
In relatia STUDENT NR_MATRICOL este cheie; iar cheia relatiei SIT.SC este formata din ansamblul atributelor NRMATRICOL, CODEXAMEN SI DATAEX. Orice valoare pentru NRMATRICOL din relatia SIT.SC trebuie sa existe in NRMATRICOL din STUDENT (idem pentru CODEXAMEN).
![]()
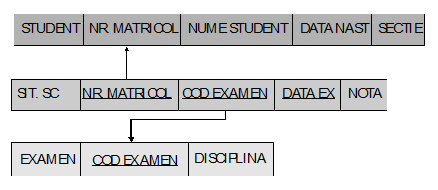
Fig. 5.3 Restrictie referentiala
Atributul NRMATRICOL (CODEX) in relatia STUDENT este numit cheie primara, iar in relatia EXAMEN este numit cheie straina. Relatia SIT.SC poate fi numita si referentiata sau desemnata, in timp ce relatiile STUDENT si EXAMEN pot fi numite referentiale sau desemnante.
Restrictia de entitate. Valorile oricarui atribut care face parte dintr-o cheie primara trebuie sa fie "nenule". Unicitatea cheii impune ca la incarcarea unui tuplu, valoarea cheii sa fie cunoscuta. In felul acesta se elimina duplicarea tuplurilor. Restrictia de integritate a entitatii nu se aplica cheilor externe dintr-o relatie, daca acestea nu apartin cheii primare.
Plecand de la restrictia de entitate, rezulta ca restrictia de referinta poate fi: forte si slaba. O restrictie de referinta este "forte" daca atributul cheii straine nu poate lua o valoare "nula". O restrictie de referinta este "slaba" daca atributul cheii straine poate lua o valoare "nula".
Pe langa restrictiile minimale, modelul relational poate oferi si restrictii referitoare la dependenta datelor si de comportament.
Restrictiile referitoare la dependenta datelor privesc datele ce depind unele de altele si pot fi: functionale, multivaloare si de jonctiune.
Dependentele functionale permit identificarea unui atribut sau grup de atribute prin intermediul altui atribut sau grup de atribute.
Dependentele multivaloare se stabilesc intre datele in care un atribut sau grup de atribute poate prezenta mai multe valori pentru o singura valoare a unui alt atribut sau grup de atribute.
Dependentele de jonctiune apar atunci cand nu se pot manifesta dependente functionale sau multivaloare, exprimand o relatie mai generala.
Restrictiile de comportament, la randul lor pot fi, cel mai adesea, de domeniu si temporale. Cele de domeniu impun ca valorile unui atribut sa se incadreze intre anumite limite. Cele temporale impun ca valorile rezultate in urma actualizarii sa fie altele decat cele anterioare actualizarii.
Avand in vedere aspectele teoretice de mai sus prezentam in continuare cele 13 reguli (numerotate de la 0 la 12) prin care E.F. Codd defineste si caracterizeaza modelul relational [9]
R0 - regula de fundamentare (regula de baza): un sistem relational de administrare a bazelor de date trebuie sa poata administra bazele de date in intregime prin functiile sale relationale; aceasta inseamna ca un SGBD relational nu trebuie sa mixeze caracteristicile relationale cu cele nerelationale, el cuprinzand o parte de definire a datelor (DDL), o parte de manipulare a datelor (DML) si o parte de integritate si control a datelor (DCL); totusi, in practica se constata ca nici o implementare curenta de SGBD nu respecta aceasta regula, deoarece contin atat caracteristici relationale cat si nerelationale;
R1 - regula reprezentarii informatiei (The Information Rule): toate informatiile dintr-o baza de date relationale sunt reprezentate la nivel logic, explicit ca valori in tabele; datele sunt stocate sub forma unor structuri tabelare, numite relatii, formate din randuri (tupluri) si coloane (atribute) ; o astfel de structura ofera o serie de avantaje precum: claritate, generalitate (majoritatea tipurilor de date pot fi reprezentate sub aceasta forma), flexibilitate (structura poate fi modificata atat pe randuri cat si pe coloane); folosind o astfel de structura, asupra datelor pot fi aplicate operatii din teoria multimilor ca: selectia, proiectia, produsul cartezian, reuniunea, intersectia etc.; Codd apreciaza ca un SGBD care nu respecta aceasta regula nu poate fi considerat relational;
R2 - regula accesului garantat la date (Guaranteed Access): intr-o baza de date relationala orice valoare are accesul garantat daca se foloseste o combinatie intre numele tabelului (relatiei), valoarea cheii primare si numele atributului; fiecare relatie trebuie sa contina o cheie primara, adica un atribut sau o combinatie de atribute, care sa identifice in mod unic un tuplu (este de remarcat, totusi, faptul ca in majoritatea implementarilor de SQL este permisa duplicarea);
R3 - regula prelucrarii sistematice a valorii nule (Systematic Null Value Support), cunoscuta si sub numele de regula reprezentarii informatiei necunoscute: SGBD-ul asigura un suport sistematic pentru tratamentul valorilor denumite "NULL" (date necunoscute sau neaplicabile la momentul respectiv), facand diferenta dintre o valoare fixata intentionat pe 0 (zero) sau un sir vid de caractere si o valoare necunoscuta; majoritatea implementarilor actuale de SQL respecta partial aceasta regula; facem precizarea ca pentru realizarea integritatii datelor in modelul relational sunt folosite cheile primare si secundare care nu permit utilizarea tipului de date "NULL";
R4 - regula dictionarului - catalogului relational activ on-line (Active On-line Relational Catalog): descrierea bazei de date si a componentelor sale este realizata la nivel logic sub forma de tabele, putand fi interogata in timp real prin intermediul limbajului de manipulare a bazei de date; toate informatiile ce privesc relatiile, vizualizarile, indexarile etc. trebuie sa poata fi stocate sub forma unor relatii ce formeaza un catalog de sistem (dictionar), si prin urmare sa poata fi accesate in acelasi mod ca si datele propriu-zise prin intermediul acelorasi comenzi; implementarile actuale de SQL respecta aceasta regula, interogarea datelor realizandu-se prin intermediul frazei SELECT;
R5 - regula limbajului de interogare sau regula sublimbajului multilateral al datelor (Comprehensive Data Sublanguage): trebuie sa existe cel putin un limbaj multilateral, cu o sintaxa bine definita si care sa permita definirea si manipularea datelor, stabilirea regulilor de integritate, autorizarea accesului si realizarea tranzactiilor; aceasta regula cere ca manipularea datelor dintr-o baza de date sa se faca prin intermediul unui limbaj de nivel inalt; in general toate implementarile SQL respecta aceasta regula;
R6 - regula actualizarii tabelelor virtuale /vederi relationale (View Updating Rule): un SGBD trebuie sa stabileasca daca o tabela virtuala poate fi actualizata si sa stocheze rezultatul interogarii intr-un dictionar de tipul unui catalog de sistem; majoritatea implementarilor SQL permit crearea unei relatii ce contine detalii referitoare la tabelele virtuale, detalii in baza carora sa se accepte sau nu operatiunea de actualizare;
R7 - regula limbajului de nivel inalt sau regula inserarii, actualizarii si stergerii la nivel de multimi (Set Level Insertion, Update and Deletion): SGBD-ul permite pe langa regasirea datelor la nivel de multimi si manipularea datelor prin inserari, actualizari si stergeri; aceste operatii trebuie sa poata fi aplicate atat in mod interactiv cat si prin intermediul unui limbaj gazda;
R8 - regula independentei fizice a datelor (Physical Data Independence): intr-un SGBD trebuie sa se separe aspectul fizic al datelor(stocarea si accesarea datelor) de aspectul logic (programele de aplicatii); deteriorarea metodelor de acces fizic sau a structurilor de memorare nu afecteaza din punct de vedere logic programele de aplicatie si utilizarile bazei;
R9 - regula independentei logice a datelor (Logical Data Independence): modificarea semantica a schemei bazei (ex. normalizarea relatiilor pentru cresterea performantelor) nu afecteaza din punct de vedere logic datele prin operatiile de manipulare;
R10 - regula independentei datelor din punct de vedere alintegritatii (Integrity Independence): limbajul bazei de date defineste regulile de integritate care trebuie respectate si memorate in catalogul relational on-line (dictionarul de date) si nu in programe; un SGBD trebuie sa permita operatii de validare a datelor, operatii gestionate prin intermediul cataloagelor de sistem (dictionare); aceste operatii nu trebuie facute prin scrierea de programe, ci prin intermediul limbajului relational, in particular SQL;
R11 - regula independentei datelor din punct de vedere al distribuirii (Distribution Independence): distribuirea datelor pe mai multe calculatoare dintr-o retea nu trebuie sa afecteze programele de aplicatii; SGBD-ul relational trebuie sa respecte independenta de distributie avand un limbaj care sa permita aplicatiilor sa ramana logic nemodificate atunci cand datele sunt transferate de la o baza de date locala la una distribuita sau atunci cand datele sunt distribuite; aceasta regula este considerata ca fiind cea mai "dura" si printre cele mai dificil de respectat ( de altfel ANSI-SQL nu o mentioneaza in specificatiile sale);
R12 - regula versiunii procedurale a SGBD sau regula de nesubversiune (Nonsubvertion): orice componenta procedurala a unui SGBD trebuie sa respecte aceleasi restrictii de integritate ca si componenta relationala (de ex. daca la manipularea datelor o data dintr-o coloana este de tipul " NOT NULL" nici o metoda de accesare a acestei coloane nu trebuie sa permita introducerea unei valori "NULL" ; atunci cand SGBD poseda un limbaj de nivel inferior (cod-masina si de asamblare) acesta nu poate incalca regulile de integritate definite prin limbajul relational al bazei de date.
In literatura de specialitate se obisnuieste ca in functie de tipul cerintelor exprimate regulile sa fie grupate in 5 categorii[10]
reguli de baza (fundamentale) R0 si R12;
reguli structurale R1 si R6;
reguli privind integritatea datelor R3 si R10;
reguli privind manipularea datelor R2, R4, R5, R7;
reguli privind independenta datelor R8, R9, R11.
Dr. E.F. Codd a extins numarul acestor reguli de la 13 publicate in 1986, la un numar de 100 in 1990. Trebuie remarcat insa, ca nici un sistem de gestiune a bazelor de date comercializat, nu respecta absolut toate regulile definite de Codd.[11] Astfel, la un SGBD trebuie apreciata masura in care acesta este relational, deci, numarul regulilor respectate. De exemplu produsul DB2 respecta doar sapte reguli din cele 13 prezentate mai sus.
NORMALizarEa BAZElor DE DATE RELATIONALE
Normalizarea. Continut si obiective
Normalizarea unei relatii consta in reprezentarea acesteia sub o forma canonica, respectand anumite criterii de definire semantica a structurii bazei de date, precum si integritatea datelor[12]
Uzual, prin normalizare se desemneaza procesul de stabilire a structurii tabelelor unei BDR, a cheilor primare, a cheilor straine si a altor restrictii. Obiectivele normalizarii sunt:
1. Eliminarea anomaliilor de actualizare.
2. Diminuarea nevoii de reorganizare periodica a modelului.
3. Reprezentarea diverselor conexiuni dintre atributele bazei.
4. Suport pentru utilizarea unor algoritmi eficienti privind cautarea tuplurilor care indeplinesc anumite conditii specificate (interogarea BD).
Inscrisa de obicei in activitatile de analiza si proiectare ale bazelor de date, normalizarea a constituit obiectul a numeroase studii; nu se poate afirma ca exista o unanimitate de idei si instrumente. Pe de alta parte, importanta normalizarii nu trebuie absolutizata. Fragmentarea tabelelor in altele mai simple are in vedere si optimizarea vitezei de acces, reducerea traficului pe retea etc. In plus, preocupari de data mai recenta vizeaza inglobarea, in normalizare, a unor concepte privind gestiunea domeniilor atributelor si extinderea sa catre tehnologia obiectuala
Teoria clasica a normalizarii este construita in jurul a cinci forme normalizate. Codd, parintele modelului relational de organizare a datelor, a definit initial trei forme normalizate[13], notate prin 1FN, 2FN si 3FN. Intrucat, intr-o prima formulare, definitia 3FN ridica ceva probleme, Codd si Boyce au elaborat o noua varianta, cunoscuta sub numele Boyce-Codd Normal Form (BCNF).
Desi este vorba, in principiu, de o formulare mai riguroasa a aceleasi 3FN, BCNF este prezentata, in majoritatea lucrarilor, separat.
Formele 4 si 5, care sunt legate de numele lui Fagin, sunt tratate mai cu retinere in literatura consacrata analizei bazelor de date relationale. Ba chiar unele lucrari, cu tenta mai pragmatica, se opresc, declarat, la 3FN pe care o considera suficienta in rezolvarea majoritatii cazurilor practice.
Fundamentul normalizarii BDR il constituie dependentele dintre atribute. Primele trei forme normalizate pot fi determinate pe baza dependentelor functionale elementare (totale) si tranzitive. Forma a patra (4FN) se bazeaza pe dependentele multivaloare, in timp ce a cincea forma normalizata (5FN) pe dependentele de jonctiune.
Prin normalizare, o relatie este descompusa reversibil, obtinandu-se o schema relationala optima. Metodologia de normalizare nu este unica si a constituit domeniu de cercetare pentru o serie intreaga de autori precum P.A. Bernstein, E.F. Codd, C. Delobel, A. Zaniola etc.
Prima forma normalizata (1FN)
Unele lucrari definesc o relatie aflata in 1FN ca acea relatie in care fiecare atribut contine o valoare atomica, altfel spus, toate atributele sunt ne-decompozabile.
In tabela FP (figura nr. 5.13) toate atributele (datele) sunt atomice. Ar putea exista o obiectiune, relativ la atributul Adresa, in sensul ca acesta trebuie descompus in atributele: Strada, Numar, ba chiar si Bloc, Scara, Etaj, Apartament, (exista SRL-uri care au ca sediu declarat locuinta proprietarilor). Avand in vedere aceasta diversitate de situatii, am preferat un singur atribut atotcuprinzator, Adresa. De aici incolo, va fi ceva mai greu sa aflam o serie de informatii, de genul: 'care dintre clienti au sediul pe strada Libertatii' sau 'care dintre furnizori au sediul la etajul 3'. Sa nu uitam, insa, ca in asemenea interogari poate fi folosit, in SQL, operatorul LIKE.
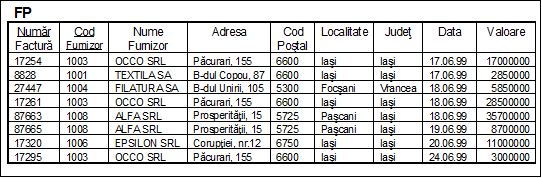 Fig. nr. 5.13. Structura tabelei
FP in 1FN
Fig. nr. 5.13. Structura tabelei
FP in 1FN
Prin urmare, in unele cazuri, declararea unui atribut ca fiind atomic sau nu tine de intentia celui care proiecteaza BD sau de flexibilitatea SGBD-ului. Spre exemplu, 'pe vremuri', atributele de tip data calendaristica erau supuse unei nemiloase descompuneri in trei atribute vadit atomice, Zi, Luna, An. Astazi, insa, orice SGBD 'lucreaza' cu atribute, variabile si constante de tip data calendaristica, astfel incat suntem scutiti de atomizarea de mai sus.
Alti autori adauga la definitia anterioara, legata de atributele atomice, si restrictia: toate atributele ce compun relatia sa fie in dependenta functionala fata de cheia relatiei, desi este, oarecum, o tautologie, intrucat una din 'poruncile' ce trebuie indeplinite de orice tabela care vrea sa fie relationala este cea cunoscuta sub numele restrictia de entitate, potrivit careia intr-o relatie nu pot exista doua tupluri identice sau, altfel spus, intr-o relatie trebuie sa existe un atribut sau combinatie de atribute ale caror valori sa deosebeasca orice tuplu de toate celelalte sau orice relatie poseda o cheie primara.
In figura nr. 5.14, tabela LINII_ARTICOLE_CONTABILE2, contine, pe primele doua linii, grupuri repetitive, pentru atributele ContDebitor, respectiv ContCreditor, datorita faptului ca operatiunile (inregistrarile) contabile din nota 150 sunt compuse.
 Fig. nr. 5.14. Tabela
LINII_ARTICOLE_CONTABILE2
Fig. nr. 5.14. Tabela
LINII_ARTICOLE_CONTABILE2
O alta acceptiune data grupurilor repetitive este legata de extinderea pe orizontala a tabelelor, prin duplicarea fortata a unor atribute. Revenim la figura nr. 5.14. Pentru a inlatura grupurile repetitive de pe primele doua linii, putem fi tentati sa modificam structura tabelei, ca in figura nr. 5.15.
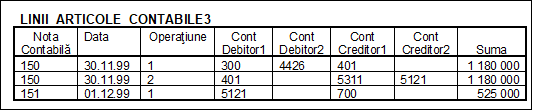 Fig. nr. 5.15. Tabela
LINII_ARTICOLE_CONTABILE3
Fig. nr. 5.15. Tabela
LINII_ARTICOLE_CONTABILE3
Solutia e cat se poate de nefericita. Desi tabela se afla in prima forma normalizata, pretul platit este mult prea mare. Deoarece, in practica, o inregistrare (operatiune) contabila poate avea 10-15 conturi pe debit sau pe credit, modificarea structurii tabelei ar deveni de-a dreptul hilara
In concluzie, tabela LINII_ARTICOLE_CONTABILE din figura nr. 5.14 este in prima forma normalizata (1FN).
Observatii
Atomicitatea atributelor intr-o baza de date relationala constituie o limita serioasa a modelului, datorita imposibilitatii adaptarii BDR la specificul unor domenii ca multimedia, CAD etc.
Nu orice tabela este in 1FN, chiar daca toate valorile atributelor sunt atomice. In conformitate cu restrictia de entitate, tuplurile relatiei trebuie sa fie distincte. In plus, atributele care alcatuiesc cheia primara nu pot avea valori nule.
Tabela FP, a carei schema este prezentata in figura nr. 5.13, se afla in 1FN, cheia sa primara fiind desemnata prin perechea (NumarFactura, CodFurnizor).
Implicit, deci, exista dependentele functionale:
(1) (NumarFactura, CodFurnizor) NumeFurnizor
(2) (NumarFactura, CodFurnizor) Adresa
(3) (NumarFactura, CodFurnizor) CodPostal
(4) (NumarFactura, CodFurnizor) Localitate
(5) (NumarFactura, CodFurnizor) Judet
(6) (NumarFactura, CodFurnizor) Data
(7) (NumarFactura, CodFurnizor) Valoare
Structura tabelei FP prezinta cateva neajunsuri, legate, in primul rand, de faptul ca nici un atribut ce face parte din cheia primara nu poate avea valori nule.
Din aceasta cauza apar probleme la adaugarea unui tuplu in relatia FP. Spre exemplu, la magazia intreprinderii au fost receptionate cateva materiale care au sosit cu un Aviz de expeditie trimis de un nou furnizor. Fiind vorba de un furnizor nou, se pune problema de a-l introduce in baza de date. I se atribuie codul 1010, i se cunoaste denumirea si sediul (adresa, localitatea). Deoarece materialele au sosit numai cu avizul de expeditie, pana la primirea facturii ne este imposibil sa introducem datele despre furnizor in tabela FP. De ce oare? Deoarece cheia primara a relatiei este compusa (NumarFactura, CodFurnizor), si nu cunoastem valoarea atributului NumarFactura, care prezinta, deocamdata, valoarea NULL (necunoscuta). Astfel, pentru a introduce date despre un nou furnizor, trebuie sa asteptam sa soseasca prima factura de la acesta, chiar daca produsele descrise in factura pot sosi cu zile sau chiar saptamani inainte.
Probleme serioase apar si la modificarea unor linii. Astfel, furnizorul ALFA SRL isi muta sediul de la adresa 'Prosperitatii, 15', noua adresa fiind 'Iacobov se intoarce, nr. 13 bis', in cadrul aceleasi localitati (Pascani).
Un client nu poate avea, la un moment dat, decat o singura adresa. Am definit in capitolul anterior, in cadrul tabelei FP dependenta functionala
CodFurnizor Adresa.
Or, daca in tabela ar co-exista si adresa veche a furnizorului, si cea noua, la o aceeasi valoare a atributului CodFurnizor ar exista doua valori distincte ale atributului Adresa
Ce facem in acest caz ? Fie renuntam la DF de mai sus, fie modificam toate vechile valori ale atributului Adresa, actualizandu-le.
Prima varianta prezinta marele dezavantaj ca altereaza partea de analiza a BDR, si, in unele cazuri, atrage revizuirea intregii scheme a BDR, deoarece vizeaza aspectul constant al relatiei, structura sa.
A doua varianta ridica, la randul sau, niste probleme deloc inaltatoare. Astfel, va trebui sa modificam valoarea atributului Adresa pentru toate facturile primite de la furnizorul respectiv, ceea ce nu e chiar simplu. Si ce-ati zice daca modificarea adresei se produce in luna mai 1997 si avem, arhivate, facturi primite de la acest furnizor inca din anul 1993 ?
Nici operatiunea de stergere a unei linii din tabela FP nu este scutita de discutii. Sa presupunem ca trebuie sa stergem linia aferenta facturii 17320, primita de la furnizorul EPSILON SRL. Dupa cum se observa in figura nr. 5.12, aceasta este singura factura primita in acest an de la furnizorul EPSILON SRL, iar facturile anului precedent au fost deja arhivate pentru a descongestiona baza de date. Stergerea singurei facturi aferente acestui furnizor atrage, inevitabil, pierderea oricarei date despre EPSILON SRL. Ulterior stergerii, la o eventuala consultare prin care s-ar dori extragerea tuturor furnizorilor firmei, EPSILON SRL nu ar mai fi 'prezent', desi, de fapt, EPSILON reprezinta un furnizor important pentru care, intamplator, in primele doua luni ale anului curent nu exista nici o factura primita.
A doua forma normalizata (2FN)
Incepand cu a doua forma normalizata, relatiile pot fi decupate in sub-relatii, in scopul diminuarii problemelor legate de stocare si actualizare.
Heath a demonstrat[14] ca orice relatie alcatuita din trei atribute, notata R(X, Y, Z), in care exista dependentele functionale X Y si X Z, poate fi descompusa in doua relatii R1(X, Y) si R2(X, Z). R1 si R2 reprezinta proiectiile relatiilor R pe atributele X si Y, respectiv X si Z.
Esential este faptul ca descompunerea se face fara pierderi de informatii, adica R poate fi 'recompusa' prin jonctiunea tabelelor R1 si R2.
O relatie se afla in 2FN daca
Se afla in 1FN.
‚ Toate DF ce leaga cheia primara la celelalte atribute sunt DF elementare (totale).
Problema trecerii unei relatii din 1FN in 2FN se pune numai cand cheia primara a relatiei este compusa din mai multe atribute.
Trecerea de la 1FN la 2FN se poate realiza dupa urmatoarea succesiune de pasi:
a) Se stabilesc dependentele totale (elementare), inclusiv cele tranzitive, cu exceptia celor in care destinatia este un atribut component al cheii primare.
b) Se trec in revista toate dependentele care au ca sursa (determinant) un atribut sau sub-ansamblu de atribute din cheia primara.
c) Pentru fiecare atribut (sau sub-ansamblu) al cheii de la pasul b), se creeaza o relatie care va avea drept identificator primar atributul (subansamblul) respectiv, iar celelalte atribute vor fi cele care apar ca destinatii in dependentele de la pasul b).
In figura nr. 5.13 a fost prezentata structura tabelei FP care este in 1FN, cheia sa primara fiind desemnata prin perechea (NumarFactura, CodFurnizor).
Conform definitiei cheii primare, exista dependentele functionale (1)-(7) identificate in paragraful 5.4.2. Intr-un paragraful anterior am vazut ca primele cinci dintre ele nu sunt elementare, datorita existentei dependentelor:
(8) CodFurnizor NumeFurnizor
(9) CodFurnizor Adresa
(10) CodFurnizor CodPostal
(11) CodFurnizor Localitate
(12) CodFurnizor Judet
Intrucat, in FP exista dependente functionale ne-elementare (partiale), rezulta ca aceasta nu este in 2FN.
Aplicam cei trei pasi pentru aducerea relatiei FP in 2FN:
a) Dependentele totale (elementare), inclusiv cele tranzitive sunt cele sapte prezentate in exemplul 1 din paragraful precedent.
b) Dependentele care au ca sursa un atribut/sub-ansamblu din cheia primara sunt (8), (9), (10), (11) si (12).
c) Daca, pentru fiecare atribut component al cheii care apare ca sursa in dependente functionale, se creeaza o relatie ce are drept identificator primar atributul respectiv, celelalte atribute fiind destinatiile dependentelor de la punctul b), relatia universala FP se sparge in doua tabele, FP1 si FP2, ale caror structuri sunt prezentate in figura nr. 5.16.
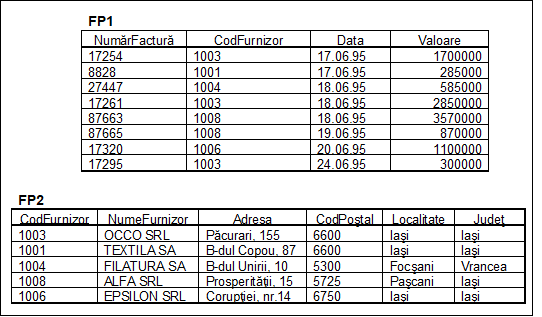 Fig. nr. 5.16. Tabelele FP1 si FP2 in 2FN
Fig. nr. 5.16. Tabelele FP1 si FP2 in 2FN
Avantaje ale 2FN
Structura prezentata in figura nr. 5.16 elimina multe din problemele ridicate de 1FN. Astfel, putem introduce date despre un nou furnizor, pana la sosirea primei facturi de la acesta, deoarece singura tabela implicata este FP2 a carei cheie primara este constituita din atributul CodFurnizor
Modificarea adresei unui furnizor afecteaza o singura linie din tabela FP2, deci au fost eliminate multe dintre anomaliile care apareau la actualizarea valorii unor atribute.
De asemenea, stergerea unei facturi primite - care presupune eliminarea unei linii din tabela FP1 - nu mai prezinta riscul eliminarii definitive a datelor generale depre un furnizor, deoarece acestea se gasesc in tabela FP2.
Problemele care persista sunt legate de tabela FP2, in sensul repetarii valorilor atributelor Localitate si Judet pentru toti furnizorii ce provin dintr-o aceeasi localitate.
A treia forma normalizata
O relatie se afla in 3FN daca:
Se afla in 1FN.
‚ Toate atributele care nu apartin cheii primare nu depind functional de un alt atribut (ansamblu de atribute) care nu face parte din cheie.
A doua conditie poate fi exprimata si in maniera: toate dependentele functionale care leaga cheia primara de celelalte atribute sunt directe (netranzitive).
Trecerea din 2FN in 3FN se face, pentru o relatie, in urmatoarea maniera
a) Se identifica toate atributele ce nu fac parte din cheie si care sunt surse ale unor dependente functionale.
b) Pentru toate atributele identificate la punctul a), se constituie cate o relatie in care cheie primara va fi atributul respectiv, iar celelate atribute destinatiile din dependentele considerate.
Observatie
Operatiile a) si b) se repeta si pentru relatiile 'proaspat' obtinute prin descompunere.
In paragraful anterior, pornind de la tabela FP, aflata in 1FN (structura sa este prezentata in figura nr. 5.13), au fost obtinute doua tabele, FP1 si FP2, ambele aflate in 2FN.
Sa analizam structura tabelei FP2. Dependentele
CodFurnizor Localitate
CodFurnizor Judet
sunt tranzitive, deoarece exista:
CodPostal Localitate
CodPostal Judet
Prin urmare, relatia FP2 nu este in a treia forma normalizata. Aplicam algoritmul descris mai sus:
a) atributul CodPostal nu face parte din cheie si constituie sursa intr-o serie de dependente functionale;
b) tabela FP2 se sparge in tabelele FP21 si FP22, ale caror structuri sunt prezentate in figura nr. 5.17.
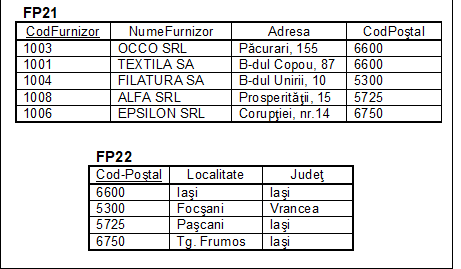
Fig. nr. 5.17. Tabelele FP21 si FP22
In concluzie, tabela FP, adusa in 3FN, se prezinta sub forma a trei tabele, FP1, FP21 si FP22, cu structurile descrise in figura nr. 5.18.
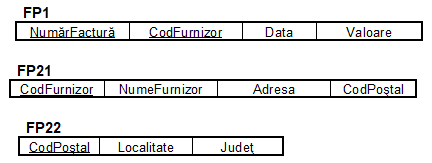
Fig. 5.18. Structura tabelelor FP1, FP21 si FP22 aflate in 3FN
Cele trei forme normalizate prezinta o importanta deosebita, considerandu-se, ca, in general, o baza de date aflata in 3FN are o structura satisfacatoare, din punct de vedere al raportului anomalii de stocare - viteza de acces (numar de jonctiuni pentru obtinerea informatiilor).
[1] Lungu, I. s.a., Baze de date - Organizare, proiectare si implementare, Editura ALL, Bucuresti, 1995, p. 96
[2] Moréjon, J., Principes et conception d'une base de données relationnelle, Les Editions d'organisation, Paris, 1992, p. 32
[3] Moréjon, J., Op. cit., p. 32
[4] Fotache, M., Baze de date relationale, Editura Junimea, Iasi, 1997, pag. 122
[5] Fotache ,M., Op. Cit., pp. 125-126
[6] Moréjon, J., Op. cit., p. 34
[7] Date, C. J., Referencial
integrity, 7th International on VLDB,
[8] Moréjon, J., Op. cit., p.35
[9] Perkins, J., Morgan, B., SQL fara profesor, in 14 zile, Editura Teora, Bucuresti, 1997, p. 23
[10] Lungu, I. s.a., Op. cit., p. 135
[11] Pascu, C., Pascu, A. , Totul despre SQL, Editura Tehnica, Bucuresti, 1994, p. 22
[12] Filip, M., Grama, A., Medii de programare. Abordari teoretice, Editura Fides, Iasi, 1998, p.204
[13]Codd, E.F., Further normalization of the database relational model, DataBase Systems, Courant Computer Science Symposia Series, Vol.6, Englewood Cliffs, N.J.,Prentice-Hall, 1972
[14] Heath,